
搜索到
26
篇与
的结果
-
 B站自动操作脚本 B站自动操作脚本,功能简介如下:1.投币、点赞、分享视频(每项操作都有经验值,如果今天已投币大于5,则不投币,否则投x个币,x为现有币的数量)2.直播签到(连续签到可以获得银瓜子,大老爷权限和月老称号)3.自动转发抽奖(计划任务每隔10分钟启动一次抽奖脚本)4.漫画APP签到(连续签到7天可以获得漫读券一张)Biliapi.pyBiliapi.py,B站操作类,后续脚本依赖这个类# -*- coding: utf-8 -*- import requests import json import re class Biliapi(object): "B站API操作" __headers = { "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36", "Referer": "https://www.bilibili.com/", } def __init__(self, cookieData): #创建session self.__session = requests.session() #添加cookie requests.utils.add_dict_to_cookiejar(self.__session.cookies, cookieData) #设置header self.__session.headers.update(Biliapi.__headers) self.__bili_jct = cookieData["bili_jct"] self.__uid = cookieData["DedeUserID"] content = self.__session.get("https://account.bilibili.com/home/reward") if json.loads(content.text)["code"] != 0: raise Exception("参数验证失败") def getReward(self): "取B站经验信息" url = "https://account.bilibili.com/home/reward" content = self.__session.get(url) return json.loads(content.text)["data"] @staticmethod def getId(url): "取B站指定视频链接的aid和cid号" content = requests.get(url, headers=Biliapi.__headers) match = re.search( 'https:\/\/www.bilibili.com\/video\/av(.*?)\/\">', content.text, 0) aid = match.group(1) match = re.search( '\"cid\":(.*?),', content.text, 0) cid = match.group(1) return {"aid": aid, "cid": cid} def getCoin(self): "获取剩余硬币数" url = "https://api.bilibili.com/x/web-interface/nav?build=0&mobi_app=web" content = self.__session.get(url) return int(json.loads(content.text)["data"]["money"]) def coin(self, aid, num, select_like): "给指定av号视频投币" url = "https://api.bilibili.com/x/web-interface/coin/add" post_data = { "aid": aid, "multiply": num, "select_like": select_like, "cross_domain": "true", "csrf": self.__bili_jct } content = self.__session.post(url, post_data) return json.loads(content.text) def share(self, aid): "分享指定av号视频" url = "https://api.bilibili.com/x/web-interface/share/add" post_data = { "aid": aid, "csrf": self.__bili_jct } content = self.__session.post(url, post_data) return json.loads(content.text) def report(self, aid, cid, progres): "B站上报观看进度" url = "http://api.bilibili.com/x/v2/history/report" post_data = { "aid": aid, "cid": cid, "progres": progres, "csrf": self.__bili_jct } content = self.__session.post(url, post_data) return json.loads(content.text) def getHomePageUrls(self): "取B站首页推荐视频地址列表" url = "https://www.bilibili.com" content = self.__session.get(url) match = re.findall( '<div class=\"info-box\"><a href=\"(.*?)\" target=\"_blank\">', content.text, 0) match = ["https:" + x for x in match] return match @staticmethod def getRegions(rid=1, num=6): "获取B站分区视频信息" url = "https://api.bilibili.com/x/web-interface/dynamic/region?ps=" + str(num) + "&rid=" + str(rid) content = requests.get(url, headers=Biliapi.__headers) datas = json.loads(content.text)["data"]["archives"] ids = [] for x in datas: ids.append({"title": x["title"], "aid": x["aid"], "bvid": x["bvid"], "cid": x["cid"]}) return ids @staticmethod def getRankings(rid=1, day=3): "获取B站分区排行榜视频信息" url = "https://api.bilibili.com/x/web-interface/ranking?rid=" + str(rid) + "&day=" + str(day) content = requests.get(url, headers=Biliapi.__headers) datas = json.loads(content.text)["data"]["list"] ids = [] for x in datas: ids.append({"title": x["title"], "aid": x["aid"], "bvid": x["bvid"], "cid": x["cid"], "coins": x["coins"], "play": x["play"]}) return ids def repost(self, dynamic_id, content="", extension='{"emoji_type":1}'): "转发B站动态" url = "https://api.vc.bilibili.com/dynamic_repost/v1/dynamic_repost/repost" post_data = { "uid": self.__uid, "dynamic_id": dynamic_id, "content": content, "extension": extension, #"at_uids": "", #"ctrl": "[]", "csrf_token": self.__bili_jct } content = self.__session.post(url, post_data) return json.loads(content.text) def getDynamicNew(self, type_list='268435455'): "取B站用户动态数据" url = "https://api.vc.bilibili.com/dynamic_svr/v1/dynamic_svr/dynamic_new?uid=" + self.__uid + "&type_list=" + type_list content = self.__session.get(url) return json.loads(content.text) @staticmethod def mangaClockIn(access_key, platform="android"): "模拟B站漫画客户端签到" url = "https://manga.bilibili.com/twirp/activity.v1.Activity/ClockIn" headers = { "User-Agent": "Mozilla/5.0 BiliComic/3.0.0", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", } post_data = { "access_key": access_key, "platform": platform } content = requests.post(url, data=post_data, headers=headers) return json.loads(content.text) def xliveSign(self): "B站直播签到" url = "https://api.live.bilibili.com/xlive/web-ucenter/v1/sign/DoSign" content = self.__session.get(url) return json.loads(content.text)BiliExp.pyBiliExp.py,负责直播签到,投币分享获取经验,模拟观看视频用来模拟用户登陆操作需要填写SESSDATA,bili_jct,DedeUserID三个参数,支持多用户,参数获取方法为:浏览器打开B站主页--》按F12打开开发者工具--》application--》cookies#!/usr/bin/env python3 # -*- coding: utf-8 -*- from Biliapi import Biliapi import logging cookieDatas = [{ "SESSDATA": "填写账户1 SESSDATA", "bili_jct": "填写账户1 bili_jct", "DedeUserID": "填写账户1 UserID", }, { "SESSDATA": "填写账户2 SESSDATA", "bili_jct": "填写账户2 bili_jct", "DedeUserID": "填写账户2 UserID", }] def bili_exp(cookieData): "B站直播签到,投币分享获取经验,模拟观看一个视频" logging.info(f': B站经验脚本开始为id为{cookieData["DedeUserID"]}的用户进行直播签到,投币点赞分享并观看一个首页视频') try: biliapi = Biliapi(cookieData) except Exception as e: logging.error(f'登录验证id为{cookieData["DedeUserID"]}的账户失败,原因为{str(e)},跳过此账户后续所有操作') return try: xliveInfo = biliapi.xliveSign() logging.info(f'bilibili直播签到信息:{str(xliveInfo)}') except Exception as e: logging.warning(f'直播签到异常,原因为{str(e)}') try: reward = biliapi.getReward() logging.info(f'经验脚本开始前经验信息 :{str(reward)}') except Exception as e: logging.warning(f'获取账户经验信息异常,原因为{str(e)},跳过此账户后续所有操作') return try: coin_num = biliapi.getCoin() except Exception as e: logging.warning(f'获取账户剩余硬币数异常,原因为{str(e)}') coin_num = 0 coin_exp_num = (50 - reward["coins_av"]) // 10 toubi_num = coin_exp_num if coin_num > coin_exp_num else coin_num try: datas = biliapi.getRegions() except Exception as e: logging.warning(f'获取B站分区视频信息异常,原因为{str(e)},跳过此账户后续所有操作') return if(toubi_num > 0): for i in range(toubi_num): try: info = biliapi.coin(datas[i]["aid"], 1, 1) logging.info(f'投币信息 :{str(info)}') except Exception as e: logging.warning(f'投币异常,原因为{str(e)}') try: info = biliapi.report(datas[5]["aid"], datas[5]["cid"], 300) logging.info(f'模拟视频观看进度上报:{str(info)}') except Exception as e: logging.warning(f'模拟视频观看异常,原因为{str(e)}') try: info = biliapi.share(datas[5]["aid"]) logging.info(f'分享视频结果:{str(info)}') except Exception as e: logging.warning(f'分享视频异常,原因为{str(e)}') logging.info(f'id为{cookieData["DedeUserID"]}的账户操作全部完成') def main(*args): try: logging.basicConfig(filename="exp.log", filemode='a', level=logging.INFO, format="%(asctime)s: %(levelname)s, %(message)s", datefmt="%Y/%d/%m %H:%M:%S") except: pass for x in cookieDatas: bili_exp(x) main()BiliLottery.pyBiliLottery.py,负责转发抽奖信息,需要定时启动#!/usr/bin/env python3 # -*- coding: utf-8 -*- from Biliapi import Biliapi import sqlite3 cookieData = { "SESSDATA": "0ad8e6d8%2C1608434698%2C1eba3*61", "bili_jct": "e85bbbe9712cf8b9160aa5921a269a97", "DedeUserID": "8466742", } def update(dynamic_id): conn = sqlite3.connect('lottery.db') cursor = conn.cursor() cursor.execute("SELECT id FROM lottery WHERE dynamic_id=?", (dynamic_id,)) result = True if cursor.fetchone() else False if not result: cursor.execute("SELECT id FROM lottery ORDER BY date ASC LIMIT 0,1") id = cursor.fetchone()[0] cursor.execute("UPDATE lottery SET dynamic_id=? WHERE id=?", (dynamic_id, id)) cursor.close() conn.commit() conn.close() return result def bili_lottery(data): try: biliapi = Biliapi(data) except Exception as e: logging.error(f'登录验证id为{data["DedeUserID"]}的账户失败,原因为{str(e)},跳过后续所有操作') return try: datas = biliapi.getDynamicNew()["data"]["cards"] except Exception as e: logging.warning(f'获取动态列表异常,原因为{str(e)},跳过后续所有操作') return for x in datas: if x.__contains__("extension") and x["extension"].__contains__("lott"): uname = x["desc"]["user_profile"]["info"]["uname"] dynamic_id = x["desc"]["dynamic_id"] if not update(dynamic_id): try: biliapi.repost(dynamic_id) logging.info(f'转发抽奖(用户名:{uname},dynamic_id:{str(dynamic_id)})成功') except Exception as e: logging.warning(f'此次转发抽奖失败,原因为{str(e)}') def main(*args): try: logging.basicConfig(filename="lottery.log", filemode='a', level=logging.INFO, format="%(asctime)s: %(levelname)s, %(message)s", datefmt="%Y/%d/%m %H:%M:%S") except: pass bili_lottery(cookieData)mangaClockIn.pymangaClockIn.py,负责B站漫画APP签到,需要access_key参数来保持登录状态,需要会手机抓包的才能拿到这个参数,我这里就不细讲了#!/usr/bin/env python3 # -*- coding: utf-8 -*- from Biliapi import Biliapi import logging access_keys = ["这里填写access_key,可以多个,用逗号分开"] def mangaClockIn(access_key): logging.info(f'B站漫画签到脚本开始为access_key({access_key}的账户签到') try: result = Biliapi.mangaClockIn(access_key) logging.info(f'签到信息为:{str(result)}') except Exception as e: logging.warning(f'签到异常,原因为{str(e)}') def main(*args): try: logging.basicConfig(filename="manga.log", filemode='a', level=logging.INFO, format="%(asctime)s: %(levelname)s, %(message)s", datefmt="%Y/%d/%m %H:%M:%S") except: pass for x in access_keys: mangaClockIn(x) main()P.S.所有脚本放在附件里,除了抽奖的脚本都可以在腾讯云函数里面运行,腾讯云函数怎么用度娘里已经有很多教程了,这里不细讲了。附件:biliexp.zip
B站自动操作脚本 B站自动操作脚本,功能简介如下:1.投币、点赞、分享视频(每项操作都有经验值,如果今天已投币大于5,则不投币,否则投x个币,x为现有币的数量)2.直播签到(连续签到可以获得银瓜子,大老爷权限和月老称号)3.自动转发抽奖(计划任务每隔10分钟启动一次抽奖脚本)4.漫画APP签到(连续签到7天可以获得漫读券一张)Biliapi.pyBiliapi.py,B站操作类,后续脚本依赖这个类# -*- coding: utf-8 -*- import requests import json import re class Biliapi(object): "B站API操作" __headers = { "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36", "Referer": "https://www.bilibili.com/", } def __init__(self, cookieData): #创建session self.__session = requests.session() #添加cookie requests.utils.add_dict_to_cookiejar(self.__session.cookies, cookieData) #设置header self.__session.headers.update(Biliapi.__headers) self.__bili_jct = cookieData["bili_jct"] self.__uid = cookieData["DedeUserID"] content = self.__session.get("https://account.bilibili.com/home/reward") if json.loads(content.text)["code"] != 0: raise Exception("参数验证失败") def getReward(self): "取B站经验信息" url = "https://account.bilibili.com/home/reward" content = self.__session.get(url) return json.loads(content.text)["data"] @staticmethod def getId(url): "取B站指定视频链接的aid和cid号" content = requests.get(url, headers=Biliapi.__headers) match = re.search( 'https:\/\/www.bilibili.com\/video\/av(.*?)\/\">', content.text, 0) aid = match.group(1) match = re.search( '\"cid\":(.*?),', content.text, 0) cid = match.group(1) return {"aid": aid, "cid": cid} def getCoin(self): "获取剩余硬币数" url = "https://api.bilibili.com/x/web-interface/nav?build=0&mobi_app=web" content = self.__session.get(url) return int(json.loads(content.text)["data"]["money"]) def coin(self, aid, num, select_like): "给指定av号视频投币" url = "https://api.bilibili.com/x/web-interface/coin/add" post_data = { "aid": aid, "multiply": num, "select_like": select_like, "cross_domain": "true", "csrf": self.__bili_jct } content = self.__session.post(url, post_data) return json.loads(content.text) def share(self, aid): "分享指定av号视频" url = "https://api.bilibili.com/x/web-interface/share/add" post_data = { "aid": aid, "csrf": self.__bili_jct } content = self.__session.post(url, post_data) return json.loads(content.text) def report(self, aid, cid, progres): "B站上报观看进度" url = "http://api.bilibili.com/x/v2/history/report" post_data = { "aid": aid, "cid": cid, "progres": progres, "csrf": self.__bili_jct } content = self.__session.post(url, post_data) return json.loads(content.text) def getHomePageUrls(self): "取B站首页推荐视频地址列表" url = "https://www.bilibili.com" content = self.__session.get(url) match = re.findall( '<div class=\"info-box\"><a href=\"(.*?)\" target=\"_blank\">', content.text, 0) match = ["https:" + x for x in match] return match @staticmethod def getRegions(rid=1, num=6): "获取B站分区视频信息" url = "https://api.bilibili.com/x/web-interface/dynamic/region?ps=" + str(num) + "&rid=" + str(rid) content = requests.get(url, headers=Biliapi.__headers) datas = json.loads(content.text)["data"]["archives"] ids = [] for x in datas: ids.append({"title": x["title"], "aid": x["aid"], "bvid": x["bvid"], "cid": x["cid"]}) return ids @staticmethod def getRankings(rid=1, day=3): "获取B站分区排行榜视频信息" url = "https://api.bilibili.com/x/web-interface/ranking?rid=" + str(rid) + "&day=" + str(day) content = requests.get(url, headers=Biliapi.__headers) datas = json.loads(content.text)["data"]["list"] ids = [] for x in datas: ids.append({"title": x["title"], "aid": x["aid"], "bvid": x["bvid"], "cid": x["cid"], "coins": x["coins"], "play": x["play"]}) return ids def repost(self, dynamic_id, content="", extension='{"emoji_type":1}'): "转发B站动态" url = "https://api.vc.bilibili.com/dynamic_repost/v1/dynamic_repost/repost" post_data = { "uid": self.__uid, "dynamic_id": dynamic_id, "content": content, "extension": extension, #"at_uids": "", #"ctrl": "[]", "csrf_token": self.__bili_jct } content = self.__session.post(url, post_data) return json.loads(content.text) def getDynamicNew(self, type_list='268435455'): "取B站用户动态数据" url = "https://api.vc.bilibili.com/dynamic_svr/v1/dynamic_svr/dynamic_new?uid=" + self.__uid + "&type_list=" + type_list content = self.__session.get(url) return json.loads(content.text) @staticmethod def mangaClockIn(access_key, platform="android"): "模拟B站漫画客户端签到" url = "https://manga.bilibili.com/twirp/activity.v1.Activity/ClockIn" headers = { "User-Agent": "Mozilla/5.0 BiliComic/3.0.0", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", } post_data = { "access_key": access_key, "platform": platform } content = requests.post(url, data=post_data, headers=headers) return json.loads(content.text) def xliveSign(self): "B站直播签到" url = "https://api.live.bilibili.com/xlive/web-ucenter/v1/sign/DoSign" content = self.__session.get(url) return json.loads(content.text)BiliExp.pyBiliExp.py,负责直播签到,投币分享获取经验,模拟观看视频用来模拟用户登陆操作需要填写SESSDATA,bili_jct,DedeUserID三个参数,支持多用户,参数获取方法为:浏览器打开B站主页--》按F12打开开发者工具--》application--》cookies#!/usr/bin/env python3 # -*- coding: utf-8 -*- from Biliapi import Biliapi import logging cookieDatas = [{ "SESSDATA": "填写账户1 SESSDATA", "bili_jct": "填写账户1 bili_jct", "DedeUserID": "填写账户1 UserID", }, { "SESSDATA": "填写账户2 SESSDATA", "bili_jct": "填写账户2 bili_jct", "DedeUserID": "填写账户2 UserID", }] def bili_exp(cookieData): "B站直播签到,投币分享获取经验,模拟观看一个视频" logging.info(f': B站经验脚本开始为id为{cookieData["DedeUserID"]}的用户进行直播签到,投币点赞分享并观看一个首页视频') try: biliapi = Biliapi(cookieData) except Exception as e: logging.error(f'登录验证id为{cookieData["DedeUserID"]}的账户失败,原因为{str(e)},跳过此账户后续所有操作') return try: xliveInfo = biliapi.xliveSign() logging.info(f'bilibili直播签到信息:{str(xliveInfo)}') except Exception as e: logging.warning(f'直播签到异常,原因为{str(e)}') try: reward = biliapi.getReward() logging.info(f'经验脚本开始前经验信息 :{str(reward)}') except Exception as e: logging.warning(f'获取账户经验信息异常,原因为{str(e)},跳过此账户后续所有操作') return try: coin_num = biliapi.getCoin() except Exception as e: logging.warning(f'获取账户剩余硬币数异常,原因为{str(e)}') coin_num = 0 coin_exp_num = (50 - reward["coins_av"]) // 10 toubi_num = coin_exp_num if coin_num > coin_exp_num else coin_num try: datas = biliapi.getRegions() except Exception as e: logging.warning(f'获取B站分区视频信息异常,原因为{str(e)},跳过此账户后续所有操作') return if(toubi_num > 0): for i in range(toubi_num): try: info = biliapi.coin(datas[i]["aid"], 1, 1) logging.info(f'投币信息 :{str(info)}') except Exception as e: logging.warning(f'投币异常,原因为{str(e)}') try: info = biliapi.report(datas[5]["aid"], datas[5]["cid"], 300) logging.info(f'模拟视频观看进度上报:{str(info)}') except Exception as e: logging.warning(f'模拟视频观看异常,原因为{str(e)}') try: info = biliapi.share(datas[5]["aid"]) logging.info(f'分享视频结果:{str(info)}') except Exception as e: logging.warning(f'分享视频异常,原因为{str(e)}') logging.info(f'id为{cookieData["DedeUserID"]}的账户操作全部完成') def main(*args): try: logging.basicConfig(filename="exp.log", filemode='a', level=logging.INFO, format="%(asctime)s: %(levelname)s, %(message)s", datefmt="%Y/%d/%m %H:%M:%S") except: pass for x in cookieDatas: bili_exp(x) main()BiliLottery.pyBiliLottery.py,负责转发抽奖信息,需要定时启动#!/usr/bin/env python3 # -*- coding: utf-8 -*- from Biliapi import Biliapi import sqlite3 cookieData = { "SESSDATA": "0ad8e6d8%2C1608434698%2C1eba3*61", "bili_jct": "e85bbbe9712cf8b9160aa5921a269a97", "DedeUserID": "8466742", } def update(dynamic_id): conn = sqlite3.connect('lottery.db') cursor = conn.cursor() cursor.execute("SELECT id FROM lottery WHERE dynamic_id=?", (dynamic_id,)) result = True if cursor.fetchone() else False if not result: cursor.execute("SELECT id FROM lottery ORDER BY date ASC LIMIT 0,1") id = cursor.fetchone()[0] cursor.execute("UPDATE lottery SET dynamic_id=? WHERE id=?", (dynamic_id, id)) cursor.close() conn.commit() conn.close() return result def bili_lottery(data): try: biliapi = Biliapi(data) except Exception as e: logging.error(f'登录验证id为{data["DedeUserID"]}的账户失败,原因为{str(e)},跳过后续所有操作') return try: datas = biliapi.getDynamicNew()["data"]["cards"] except Exception as e: logging.warning(f'获取动态列表异常,原因为{str(e)},跳过后续所有操作') return for x in datas: if x.__contains__("extension") and x["extension"].__contains__("lott"): uname = x["desc"]["user_profile"]["info"]["uname"] dynamic_id = x["desc"]["dynamic_id"] if not update(dynamic_id): try: biliapi.repost(dynamic_id) logging.info(f'转发抽奖(用户名:{uname},dynamic_id:{str(dynamic_id)})成功') except Exception as e: logging.warning(f'此次转发抽奖失败,原因为{str(e)}') def main(*args): try: logging.basicConfig(filename="lottery.log", filemode='a', level=logging.INFO, format="%(asctime)s: %(levelname)s, %(message)s", datefmt="%Y/%d/%m %H:%M:%S") except: pass bili_lottery(cookieData)mangaClockIn.pymangaClockIn.py,负责B站漫画APP签到,需要access_key参数来保持登录状态,需要会手机抓包的才能拿到这个参数,我这里就不细讲了#!/usr/bin/env python3 # -*- coding: utf-8 -*- from Biliapi import Biliapi import logging access_keys = ["这里填写access_key,可以多个,用逗号分开"] def mangaClockIn(access_key): logging.info(f'B站漫画签到脚本开始为access_key({access_key}的账户签到') try: result = Biliapi.mangaClockIn(access_key) logging.info(f'签到信息为:{str(result)}') except Exception as e: logging.warning(f'签到异常,原因为{str(e)}') def main(*args): try: logging.basicConfig(filename="manga.log", filemode='a', level=logging.INFO, format="%(asctime)s: %(levelname)s, %(message)s", datefmt="%Y/%d/%m %H:%M:%S") except: pass for x in access_keys: mangaClockIn(x) main()P.S.所有脚本放在附件里,除了抽奖的脚本都可以在腾讯云函数里面运行,腾讯云函数怎么用度娘里已经有很多教程了,这里不细讲了。附件:biliexp.zip -
Python 资源大全中文版 Python 资源大全中文版我想很多程序员应该记得 GitHub 上有一个 Awesome - XXX 系列的资源整理。awesome-python 是 vinta 发起维护的 Python 资源列表,内容包括:Web 框架、网络爬虫、网络内容提取、模板引擎、数据库、数据可视化、图片处理、文本处理、自然语言处理、机器学习、日志、代码分析等。由伯乐在线持续更新。Awesome 系列虽然挺全,但基本只对收录的资源做了极为简要的介绍,如果有更详细的中文介绍,对相应开发者的帮助会更大。这也是我们发起这个开源项目的初衷。关于项目我们要做什么?基于 awesome-python 列表,我们将对其中的各个资源项进行编译整理。此外还将从其他来源补充好资源。整理后的内容,将收录在伯乐在线资源频道。可参考已整理的内容:《Scrapy:Python 的爬虫框架》《Flask:一个使用 Python 编写的轻量级 Web 应用框架》如何为列表贡献新资源?欢迎大家为列表贡献高质量的新资源,提交 PR 时请参照以下要求:请确保推荐的资源自己使用过提交 PR 时请注明推荐理由资源列表管理收到 PR 请求后,会定期(每周)在微博转发本周提交的 PR 列表,并在微博上面听取使用过这些资源的意见。确认通过后,会加入资源大全。感谢您的贡献!本项目的参与者维护者:贡献者:艾凌风、Namco、Daetalus、黄利民、atupal、rainbow、木头lbj、beyondwu、cissoid、李广胜、polyval、冰斌、赵叶宇、л stalgic、硕恩、strongit、yuukilp、chenjiandongx、autopenguin、visonforcoding、Super赛亚人、Since-future、knktc、zhucebuliaopx、wardseptember注:名单不分排名,不定期补充更新资源列表环境管理管理 Python 版本和环境的工具p:非常简单的交互式 python 版本管理工具。官网pyenv:简单的 Python 版本管理工具。官网Vex:可以在虚拟环境中执行命令。官网virtualenv:创建独立 Python 环境的工具。官网virtualenvwrapper:virtualenv 的一组扩展。官网buildout:在隔离环境初始化后使用声明性配置管理。官网包管理管理包和依赖的工具。pip:Python 包和依赖关系管理工具。官网pip-tools:保证 Python 包依赖关系更新的一组工具。官网pipenv:Python 官方推荐的新一代包管理工具。官网poetry: 可完全取代 setup.py 的包管理工具。官网conda:跨平台,Python 二进制包管理工具。官网Curdling:管理 Python 包的命令行工具。官网wheel:Python 分发的新标准,意在取代 eggs。官网包仓库本地 PyPI 仓库服务和代理。warehouse:下一代 PyPI。官网bandersnatch:PyPA 提供的 PyPI 镜像工具。官网devpi:PyPI 服务和打包/测试/分发工具。官网localshop:本地 PyPI 服务(自定义包并且自动对 PyPI 镜像)。官网分发打包为可执行文件以便分发。PyInstaller:将 Python 程序转换成独立的执行文件(跨平台)。官网cx_Freeze:将python程序转换为带有一个动态链接库的可执行文件。官网dh-virtualenv:构建并将 virtualenv 虚拟环境作为一个 Debian 包来发布。官网Nuitka:将脚本、模块、包编译成可执行文件或扩展模块。官网py2app:将 Python 脚本变为独立软件包(Mac OS X)。官网py2exe:将 Python 脚本变为独立软件包(Windows)。官网pynsist:一个用来创建 Windows 安装程序的工具,可以在安装程序中打包 Python 本身。官网构建工具将源码编译成软件。buildout:一个构建系统,从多个组件来创建,组装和部署应用。官网BitBake:针对嵌入式 Linux 的类似 make 的构建工具。官网fabricate:对任何语言自动找到依赖关系的构建工具。官网PlatformIO:多平台命令行构建工具。官网PyBuilder:纯 Python 实现的持续化构建工具。官网SCons:软件构建工具。官网交互式解析器交互式 Python 解析器。IPython:功能丰富的工具,非常有效的使用交互式 Python。官网bpython:界面丰富的 Python 解析器。官网ptpython:高级交互式 Python 解析器, 构建于 python-prompt-toolkit 之上。官网文件文件管理和 MIME(多用途的网际邮件扩充协议)类型检测。aiofiles:基于 asyncio,提供文件异步操作。官网imghdr:(Python 标准库)检测图片类型。官网mimetypes:(Python 标准库)将文件名映射为 MIME 类型。官网path.py:对 os.path 进行封装的模块。官网pathlib:(Python3.4+ 标准库)跨平台的、面向对象的路径操作库。官网python-magic:文件类型检测的第三方库 libmagic 的 Python 接口。官网Unipath:用面向对象的方式操作文件和目录。官网watchdog:管理文件系统事件的 API 和 shell 工具。官网日期和时间操作日期和时间的类库。arrow:更好的 Python 日期时间操作类库。官网Chronyk:Python 3 的类库,用于解析手写格式的时间和日期。官网dateutil:Python datetime 模块的扩展。官网delorean:解决 Python 中有关日期处理的棘手问题的库。官网maya:人性化的时间处理库。官网moment:一个用来处理时间和日期的 Python 库。灵感来自于 Moment.js。官网pendulum:一个比 arrow 更具有明确的,可预测的行为的时间操作库。官网PyTime:一个简单易用的 Python 模块,用于通过字符串来操作日期/时间。官网pytz:现代以及历史版本的世界时区定义。将时区数据库引入 Python。官网when.py:提供用户友好的函数来帮助用户进行常用的日期和时间操作。官网文本处理用于解析和操作文本的库。通用chardet:字符编码检测器,兼容 Python2 和 Python3。官网difflib:(Python 标准库)帮助我们进行差异化比较。官网ftfy:让 Unicode 文本更完整更连贯。官网fuzzywuzzy:模糊字符串匹配。官网Levenshtein:快速计算编辑距离以及字符串的相似度。官网pangu.py:在中日韩语字符和数字字母之间添加空格。官网pypinyin:汉字拼音转换工具 Python 版。官网shortuuid:一个生成器库,用以生成简洁的,明白的,URL 安全的 UUID。官网simplejson:Python 的 JSON 编码、解码器。官网unidecode:Unicode 文本的 ASCII 转换形式 。官网uniout:打印可读的字符,而不是转义的字符串。官网xpinyin:一个用于把汉字转换为拼音的库。官网yfiglet-figlet:pyfiglet -figlet 的 Python 实现。flashtext: 一个高效的文本查找替换库。官网Slug 化awesome-slugify:一个 Python slug 化库,可以保持 Unicode。官网python-slugify:Python slug 化库,可以把 unicode 转化为 ASCII。官网unicode-slugify:一个 slug 工具,可以生成 unicode slugs ,需要依赖 Django 。官网解析器phonenumbers:解析,格式化,储存,验证电话号码。官网PLY:lex 和 yacc 解析工具的 Python 实现。官网Pygments:通用语法高亮工具。官网pyparsing:生成通用解析器的框架。官网python-nameparser:把一个人名分解为几个独立的部分。官网python-user-agents:浏览器 user agent 解析器。官网sqlparse:一个无验证的 SQL 解析器。官网特殊文本格式处理一些用来解析和操作特殊文本格式的库。通用tablib:一个用来处理中表格数据的模块。官网OfficeMarmir:把输入的 Python 数据结构转换为电子表单。官网openpyxl:一个用来读写 Excel 2010 xlsx/xlsm/xltx/xltm 文件的库。官网pyexcel:一个提供统一 API,用来读写,操作 Excel 文件的库。官网python-docx:读取,查询以及修改 Microsoft Word 2007/2008 docx 文件。官网relatorio:模板化 OpenDocument 文件。官网unoconv:在 LibreOffice/OpenOffice 支持的任意文件格式之间进行转换。官网XlsxWriter:一个用于创建 Excel .xlsx 文件的 Python 模块。官网xlwings:一个使得在 Excel 中方便调用 Python 的库(反之亦然),基于 BSD 协议。官网xlwt:读写 Excel 文件的数据和格式信息。官网 / xlrdPDFPDFMiner:一个用于从 PDF 文档中抽取信息的工具。官网PyPDF2:一个可以分割,合并和转换 PDF 页面的库。官网ReportLab:快速创建富文本 PDF 文档。官网MarkdownMistune:快速并且功能齐全的纯 Python 实现的 Markdown 解析器。官网Python-Markdown:John Gruber’s Markdown 的 Python 版实现。官网Python-Markdown2:纯 Python 实现的 Markdown 解析器,比 Python-Markdown 更快,更准确,可扩展。官网YAMLPyYAML:Python 版本的 YAML 解析器。官网CSVcsvkit:用于转换和操作 CSV 的工具。官网Archiveunp:一个用来方便解包归档文件的命令行工具。官网自然语言处理用来处理人类语言的库。NLTK:一个先进的平台,用以构建处理人类语言数据的 Python 程序。官网jieba:中文分词工具。官网langid.py:独立的语言识别系统。官网Pattern:Python 网络信息挖掘模块。官网SnowNLP:一个用来处理中文文本的库。官网TextBlob:为进行普通自然语言处理任务提供一致的 API。官网TextGrocery:一简单高效的短文本分类工具,基于 LibLinear 和 Jieba。官网thulac:清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包官网文档用以生成项目文档的库。Sphinx:Python 文档生成器。官网awesome-sphinxdoc:官网MkDocs:对 Markdown 友好的文档生成器。官网pdoc:一个可以替换 Epydoc 的库,可以自动生成 Python 库的 API 文档。官网Pycco:文学编程(literate-programming)风格的文档生成器。官网readthedocs:一个基于 Sphinx/MkDocs 的在线文档托管系统,对开源项目免费开放使用。官网配置用来保存和解析配置的库。config:logging 模块作者写的分级配置模块。官网ConfigObj:INI 文件解析器,带验证功能。官网ConfigParser:(Python 标准库) INI 文件解析器。官网profig:通过多种格式进行配置,具有数值转换功能。官网python-decouple:将设置和代码完全隔离。官网命令行工具用于创建命令行程序的库。命令行程序开发asciimatics:跨平台,全屏终端包(即鼠标/键盘输入和彩色,定位文本输出),完整的复杂动画和特殊效果的高级 API。官网cement:Python 的命令行程序框架。官网click:一个通过组合的方式来创建精美命令行界面的包。官网cliff:一个用于创建命令行程序的框架,可以创建具有多层命令的命令行程序。官网clint:Python 命令行程序工具。官网colorama:跨平台彩色终端文本。官网docopt:Python 风格的命令行参数解析器。官网Gooey:一条命令,将命令行程序变成一个 GUI 程序。官网python-prompt-toolkit:一个用于构建强大的交互式命令行程序的库。官网python-fire:Google 出品的一个基于 Python 类的构建命令行界面的库。官网Pythonpy:在命令行中直接执行任何 Python 指令。官网生产力工具aws-cli:Amazon Web Services 的通用命令行界面。官网bashplotlib:在终端中进行基本绘图。官网caniusepython3:判断是哪个项目妨碍你你移植到 Python3。官网cookiecutter:从 cookiecutters(项目模板)创建项目的一个命令行工具。官网doitlive:一个用来在终端中进行现场演示的工具。官网pyftpdlib:一个速度极快和可扩展的 Python FTP 服务库。官网howdoi:通过命令行获取即时的编程问题解答。官网httpie:一个命令行 HTTP 客户端,cURL 的替代品,易用性更好。官网PathPicker:从 bash 输出中选出文件。官网percol:向 UNIX shell 传统管道概念中加入交互式选择功能。官网SAWS:一个加强版的 AWS 命令行。官网thefuck:修正你之前的命令行指令。官网mycli:一个 MySQL 命令行客户端,具有自动补全和语法高亮功能。官网pgcli:Postgres 命令行工具,具有自动补全和语法高亮功能。官网try:一个从来没有更简单的命令行工具,用来试用 python 库。官网下载器用来进行下载的库.s3cmd:一个用来管理 Amazon S3 和 CloudFront 的命令行工具。官网s4cmd:超级 S3 命令行工具,性能更加强劲。官网you-get:一个 YouTube/Youku/Niconico 视频下载器,使用 Python3 编写。官网youtube-dl:一个小巧的命令行程序,用来下载 YouTube 视频。官网图像处理用来操作图像的库.pillow:Pillow 是一个更加易用版的 PIL。官网hmap:图像直方图映射。官网imgSeek:一个使用视觉相似性搜索一组图片集合的项目。官网nude.py:裸体检测。官网pyBarcode:不借助 PIL 库在 Python 程序中生成条形码。官网pygram:类似 Instagram 的图像滤镜。官网python-qrcode:一个纯 Python 实现的二维码生成器。官网Quads:基于四叉树的计算机艺术。官网scikit-image:一个用于(科学)图像处理的 Python 库。官网thumbor:一个小型图像服务,具有剪裁,尺寸重设和翻转功能。官网wand:MagickWand的 Python 绑定。MagickWand 是 ImageMagick 的 C API 。官网face_recognition:简单易用的 python 人脸识别库。官网OCR光学字符识别库。pyocr:Tesseract 和 Cuneiform 的一个封装(wrapper)。官网pytesseract:Google Tesseract OCR 的另一个封装(wrapper)。官网python-tesseract:Google Tesseract OCR 的一个包装类。音频用来操作音频的库audiolazy:Python 的数字信号处理包。官网audioread:交叉库 (GStreamer + Core Audio + MAD + FFmpeg) 音频解码。官网beets:一个音乐库管理工具及 MusicBrainz 标签添加工具。官网dejavu:音频指纹提取和识别。官网django-elastic-transcoder:Django + Amazon Elastic Transcoder。官网eyeD3:一个用来操作音频文件的工具,具体来讲就是包含 ID3 元信息的 MP3 文件。官网id3reader:一个用来读取 MP3 元数据的 Python 模块。官网m3u8:一个用来解析 m3u8 文件的模块。官网mutagen:一个用来处理音频元数据的 Python 模块。官网pydub:通过简单、简洁的高层接口来操作音频文件。官网pyechonest:Echo Nest API 的 Python 客户端。官网talkbox:一个用来处理演讲/信号的 Python 库。官网TimeSide:开源 web 音频处理框架。官网tinytag:一个用来读取 MP3, OGG, FLAC 以及 Wave 文件音乐元数据的库。官网mingus:一个高级音乐理论和曲谱包,支持 MIDI 文件和回放功能。官网Video用来操作视频和 GIF 的库。moviepy:一个用来进行基于脚本的视频编辑模块,适用于多种格式,包括动图 GIFs。官网scikit-video:SciPy 视频处理常用程序。官网地理位置地理编码地址以及用来处理经纬度的库。GeoDjango:世界级地理图形 web 框架。官网GeoIP:MaxMind GeoIP Legacy 数据库的 Python API。官网geojson:GeoJSON 的 Python 绑定及工具。官网geopy:Python 地址编码工具箱。官网GeoIP2:GeoIP2 Webservice 客户端与数据库 Python API。官网django-countries:一个 Django 应用程序,提供用于表格的国家选择功能,国旗图标静态文件以及模型中的国家字段。官网HTTP使用 HTTP 的库。aiohttp:基于 asyncio 的异步 HTTP 网络库。官网requests:人性化的 HTTP 请求库。官网grequests:requests 库 + gevent ,用于异步 HTTP 请求.官网httplib2:全面的 HTTP 客户端库。官网treq:类似 requests 的 Python API 构建于 Twisted HTTP 客户端之上。官网urllib3:一个具有线程安全连接池,支持文件 post,清晰友好的 HTTP 库。官网数据库Python 实现的数据库。pickleDB:一个简单,轻量级键值储存数据库。官网PipelineDB:流式 SQL 数据库。官网TinyDB:一个微型的,面向文档型数据库。官网ZODB:一个 Python 原生对象数据库。一个键值和对象图数据库。官网数据库驱动用来连接和操作数据库的库。MySQL:awesome-mysql 系列aiomysql:基于 asyncio 的异步 MySQL 数据库操作库。官网mysql-python:Python 的 MySQL 数据库连接器。官网ysqlclient:mysql-python 分支,支持 Python 3。oursql:一个更好的 MySQL 连接器,支持原生预编译指令和 BLOBs。官网PyMySQL:纯 Python MySQL 驱动,兼容 mysql-python。官网PostgreSQLpsycopg2:Python 中最流行的 PostgreSQL 适配器。官网queries:psycopg2 库的封装,用来和 PostgreSQL 进行交互。官网txpostgres:基于 Twisted 的异步 PostgreSQL 驱动。官网其他关系型数据库apsw:另一个 Python SQLite 封装。官网dataset:在数据库中存储 Python 字典pymssql:一个简单的 Microsoft SQL Server 数据库接口。官网NoSQL 数据库asyncio-redis:基于 asyncio 的 redis 客户端 (PEP 3156)。官网cassandra-python-driver:Cassandra 的 Python 驱动。官网HappyBase:一个为 Apache HBase 设计的,对开发者友好的库。官网Plyvel:一个快速且功能丰富的 LevelDB 的 Python 接口。官网py2neo:Neo4j restful 接口的 Python 封装客户端。官网pycassa:Cassandra 的 Python Thrift 驱动。官网PyMongo:MongoDB 的官方 Python 客户端。官网redis-py:Redis 的 Python 客户端。官网telephus:基于 Twisted 的 Cassandra 客户端。官网txRedis:基于 Twisted 的 Redis 客户端。官网ORM实现对象关系映射或数据映射技术的库。关系型数据库Django Models:Django 的一部分。官网SQLAlchemy:Python SQL 工具以及对象关系映射工具。官网awesome-sqlalchemy 系列Peewee:一个小巧,富有表达力的 ORM。官网PonyORM:提供面向生成器的 SQL 接口的 ORM。官网python-sql:编写 Python 风格的 SQL 查询。官网NoSQL 数据库django-mongodb-engine:Django MongoDB 后端。官网PynamoDB:Amazon DynamoDB 的一个 Python 风格接口。官网flywheel:Amazon DynamoDB 的对象映射工具。官网MongoEngine:一个 Python 对象文档映射工具,用于 MongoDB。官网hot-redis:为 Redis 提供 Python 丰富的数据类型。官网redisco:一个 Python 库,提供可以持续存在在 Redis 中的简单模型和容器。官网其他butterdb:Google Drive 电子表格的 Python ORM。官网Web 框架全栈 Web 框架。Django:Python 界最流行的 web 框架。官网awesome-django 系列Flask:一个 Python 微型框架。官网awesome-flask 系列pyramid:一个小巧,快速,接地气的开源 Python web 框架。awesome-pyramid 系列Bottle:一个快速小巧,轻量级的 WSGI 微型 web 框架。官网CherryPy:一个极简的 Python web 框架,服从 HTTP/1.1 协议且具有 WSGI 线程池。官网TurboGears:一个可以扩展为全栈解决方案的微型框架。官网web.py:一个 Python 的 web 框架,既简单,又强大。官网web2py:一个全栈 web 框架和平台,专注于简单易用。官网Tornado:一个 web 框架和异步网络库。官网sanic:基于 Python3.5+ 的异步网络框架。官网starlette: 一款轻量级,高性能的 ASGI 框架
-
分享无聊写的Python猜数字游戏 说明通常由两个人玩,一方出数字,一方猜。出数字的人要想好一个没有重复数字的4 位数序列,不能让猜的人知道。猜的人就可以开始猜。每猜一次, 出数者就要根据这个数字给出几A几B,其中A前面的数字表示位置正确的数的个数,而B前的数字表示数字正确而位置不对的数的个数。如正确答案为5234, 而猜的人猜5346,则是1A2B,其中有一个5的位置对了,记为1A,而3和4这两个数字对了,而位置没对,因此记为2B,合起来就是1A2B。CODE#! -*- coding:utf-8 -*- import random def go_game(): num = random.randint(0000,9999) #随机出四位数字 while(True): index_mate = 0 #下标正确数量 num_mate = 0 #数字正确数量 nums = input("请输入一个四位数字进行竞猜:") #输入竞猜数字 if nums == "admin": print("1.重置数字 2.查看当前数字 3.修改当前数字 4.继续竞猜 5.退出") command = input("请输入选项:") if command == "1": num = random.randint(0000,9999) print("重置成功!") continue elif command == "2": print(num) continue elif command == "3": num = input("请输入四位数字") print("设置成功,当前设置的数字为:"+num) continue elif command == "4": continue elif command == "5": break else: print("指令输入错误!") continue for i in range(0,4): list_num = list(str(num)) list_nums = list(str(nums)) if list_num[i] == list_nums[i]: index_mate = index_mate + 1 #如果当前下标的数字相同,就+1 else: for sb in range(0,len(list_nums)): if list_num[i] == list_nums[sb]: num_mate = num_mate + 1 if index_mate == 4 and num_mate == 0: print("恭喜你,猜对了!") break else: print(str(index_mate)+"A"+str(num_mate)+"B") continue go_game()
-
Python技巧备忘录 py功能模块格式化字符串 f-string(最低 Python 版本为 3.6)路径管理库 Pathlib(最低 Python 版本为 3.4)类型提示 Type hinting(最低 Python 版本为 3.5)枚举 enum (最低 Python 版本为 3.4)原生 LRU 缓存(最低 Python 版本为 3.2)Data class 装饰器(最低 Python 版本为 3.7)隐式命名空间包(最低 Python 版本为 3.3)hashlib加密模块MD5模块在python3由于加密前需要先进行encode转码,所以许多字符的md5值在py2与py3下都是不同的,当前环境下py2较符合测试python2 = hashlib.md5('abc').hexdigest() python3 = hashlib.md5('abc'.encode('utf-8').hexdigest()生成器使用生成器,会减少内存使用。这里说一下generator和函数的执行流程,函数是顺序执行的,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次被next()调用时候从上次的返回yield语句处急需执行,也就是用多少,取多少,不占内存,给调用者返回一个值,同时保留了当前的足够多的状态,可以使函数继续执行。为了避免NEXT()生成无限循环序列,可以改为循环。# 函数有了yield之后,函数名+()就变成了生成器 # return在生成器中代表生成器的中止,直接报错 # next的作用是唤醒并继续执行 # send的作用是唤醒并继续执行,发送一个信息到生成器内部 '''生成器''' def create_counter(n): print("create_counter") while True: yield n print("increment n") n +=1 gen = create_counter(2) print(gen) print(next(gen)) print(next(gen)) 结果: <generator object create_counter at 0x0000023A1694A938> create_counter 2 increment n 3 Process finished with exit code 0生成器表达式:>>> # 列表解析生成列表 >>> [ x ** 3 for x in range(5)] [0, 1, 8, 27, 64] >>> >>> # 生成器表达式 >>> (x ** 3 for x in range(5)) <generator object <genexpr> at 0x000000000315F678> >>> # 两者之间转换 >>> list(x ** 3 for x in range(5)) [0, 1, 8, 27, 64]迭代器可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。可以使用isinstance()判断一个对象是否是Iterator对象:>>> from collections import Iterator >>> isinstance((x for x in range(10)), Iterator) True >>> isinstance([], Iterator) False >>> isinstance({}, Iterator) False >>> isinstance('abc', Iterator) False生成器都是Iterator对象,但list、dict、str虽然是Iterable(可迭代对象),却不是Iterator(迭代器)。因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。traceback使用跟踪执行信息 def test_traceback(): import traceback #返回调用堆栈(一个list),最多两层, 其中最后一个元素为当前行的信息,包括(文件名,行号,函数名,这一行的代码) info = traceback.extract_stack(limit=2) print(info) # 打印函数调用堆栈 # traceback.print_stack(limit=2) # 无异常时为None # traceback.print_exc()2to3.exe将py2的代码转换为3,一般使用-w参数保留备份按照代码转换 2to3.exe -w split.py 按照目录转换 2to3.exe -w d:\object时间函数库time,datetime将错误异常写为log文件import datetime except Exception as identifier: error_log = open('log.txt','w+') now_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') error_log.write(username+' '+now_time+" "+str(identifier)+'\n') Python 引入了 with 语句来自动帮我们调用 close() 方法python之字符串格式化(format)用法:它通过{}和:来代替传统%方式使用位置参数 >>> li = ['hoho',18] >>> 'my name is {} ,age {}'.format(*li) 'my name is hoho ,age 18' >>> 'my name is {1} ,age {0} {1}'.format(10,'hoho') 'my name is hoho ,age 10 hoho' 使用关键字参数 >>> hash = {'name':'hoho','age':18} >>> 'my name is {name},age is {age}'.format(name='hoho',age=19) 'my name is hoho,age is 19' >>> 'my name is {name},age is {age}'.format(**hash) 'my name is hoho,age is 18' 填充与格式化 >>> '{0:*>10}'.format(10) ## 右对齐 '********10' >>> '{0:*<10}'.format(10) ## 左对齐 '10********' >>> '{0:*^10}'.format(10) ## 居中对齐 '****10****' 精度与进制 >>> '{0:.2f}'.format(1/3) '0.33' >>> '{0:b}'.format(10) #二进制 '1010' >>> '{0:o}'.format(10) #八进制 '12' >>> '{0:x}'.format(10) #16进制 'a' >>> '{:,}'.format(12369132698) #千分位格式化 '12,369,132,698'os模块python中对文件、文件夹操作时经常用到的os模块和shutil模块常用方法在Python的string前面加上‘r’, 是为了告诉编译器这个string是个raw string,不要转意backslash '\' 。例如,\n 在raw string中,是两个字符,\和n, 而不会转意为换行符。由于正则表达式和 \ 会有冲突,因此,当一个字符串使用了正则表达式后,最好在前面加上'r'。google_path = r'Google\Chrome\User Data\Default\Login Data'在操作系统中定义的环境变量,全部保存在os.environ这个变量中,可以直接查看:>>> os.environ environ({'VERSIONER_PYTHON_PREFER_32_BIT': 'no', 'TERM_PROGRAM_VERSION': '326', 'LOGNAME': 'michael', 'USER': 'michael', 'PATH': '/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/opt/X11/bin:/usr/local/mysql/bin', ...}) 要获取某个环境变量的值,可以调用os.environ.get('key'): >>> os.environ.get('PATH') '/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/opt/X11/bin:/usr/local/mysql/bin' >>> os.environ.get('x', 'default') 'default' 或者 os.environ['LOCALAPPDATA']join方法:连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串os.path.join(): 将多个路径组合后返回 >>> seq3 = ('hello','good','boy','doiido') >>> print ':'.join(seq3) hello:good:boy:doiido seq4 = {'hello':1,'good':2,'boy':3,'doiido':4} >>> print ':'.join(seq4) boy:good:doiido:hello 1.得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd() 2.返回指定目录下的所有文件和目录名:os.listdir() 3.函数用来删除一个文件:os.remove() 4.删除多个目录:os.removedirs(r"c:\python") 5.检验给出的路径是否是一个文件:os.path.isfile() 6.检验给出的路径是否是一个目录:os.path.isdir() 7.判断是否是绝对路径:os.path.isabs() 8.检验给出的路径是否真地存:os.path.exists() 9.返回一个路径的目录名和文件名:os.path.split() eg os.path.split(‘/home/swaroop/byte/code/poem.txt’) 结果:(‘/home/swaroop/byte/code’, ‘poem.txt’) 10.分离扩展名:os.path.splitext() 11.获取路径名:os.path.dirname() 12.获取文件名:os.path.basename() 13.运行shell命令 在子终端运行系统命令,不能获取命令执行后的返回信息以及执行返回的状态 import os os.system('date') # 2016年 06月 30日 星期四 19:26:21 CST 不仅执行命令而且返回执行后的信息对象(常用于需要获取执行命令后的返回信息) import os nowtime = os.popen('date') print nowtime.read() # 2016年 06月 30日 星期四 19:26:21 CST commands模块 |方法 |说明| |getoutput |获取执行命令后的返回信息| |getstatus |获取执行命令的状态值(执行命令成功返回数值0,否则返回非0)| |getstatusoutput |获取执行命令的状态值以及返回信息| import commonds status, output = commands.getstatusoutput('date') print status # 0 print output # 2016年 06月 30日 星期四 19:26:21 CST subprocess模块 运用对线程的控制和监控,将返回的结果赋于一变量,便于程序的处理。 官方文档:http://python.usyiyi.cn/python_278/library/subprocess.html import subprocess nowtime = subprocess.Popen('date', shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) print nowtime.stdout.read() # 2016年 06月 30日 星期四 19:26:21 CST 14.读取和设置环境变量:os.getenv() 与os.putenv() 15.给出当前平台使用的行终止符:os.linesep Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’ 16.指示你正在使用的平台:os.name 对于Windows,它是’nt’,而对于Linux/Unix用户,它是’posix’ 17.重命名:os.rename(old, new) 18.创建多级目录:os.makedirs(r"c:\python\test") 19.创建单个目录:os.mkdir("test") 20.获取文件属性:os.stat(file) 21.修改文件权限与时间戳:os.chmod(file) 22.终止当前进程:os.exit() 23.获取文件大小:os.path.getsize(filename)文本文件操作:1.os.mknod("test.txt") #创建空文件 2.fp = open("test.txt",w) #直接打开一个文件,如果文件不存在则创建文件 3.关于open 模式: w:以写方式打开, a:以追加模式打开 (从 EOF 开始, 必要时创建新文件) r+:以读写模式打开 w+:以读写模式打开 (参见 w ) a+:以读写模式打开 (参见 a ) rb:以二进制读模式打开 wb:以二进制写模式打开 (参见 w ) ab:以二进制追加模式打开 (参见 a ) rb+:以二进制读写模式打开 (参见 r+ ) wb+:以二进制读写模式打开 (参见 w+ ) ab+:以二进制读写模式打开 (参见 a+ ) fp.read([size]) #size为读取的长度,以byte为单位 fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分 fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。 fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符 fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。 fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError fp.flush() #把缓冲区的内容写入硬盘 fp.fileno() #返回一个长整型的"文件标签" fp.isatty() #文件是否是一个终端设备文件(unix系统中的) fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点 fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。 fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。目录操作方法大全1.创建目录 os.mkdir("file") 2.复制文件: shutil.copyfile("oldfile","newfile") #oldfile和newfile都只能是文件 3.复制文件夹: shutil.copy("oldfile","newfile") #oldfile只能是文件夹,newfile可以是文件,也可以是目标目录 4.shutil.copytree("olddir","newdir") #olddir和newdir都只能是目录,且newdir必须不存在 5.重命名文件(目录) os.rename("oldname","newname") #文件或目录都是使用这条命令 6.移动文件(目录) shutil.move("oldpos","newpos") 7.删除文件 os.remove("file") 8.删除目录 os.rmdir("dir") #只能删除空目录 shutil.rmtree("dir") #空目录、有内容的目录都可以删 9.转换目录 os.chdir("path") #换路径codecs进行文件的读取python给我们提供了一个包codecs进行文件的读取,这个包中的open()函数可以指定编码的类型: import codecs f = codecs.open('text.text','r+',encoding='utf-8')#必须事先知道文件的编码格式,这里文件编码是使用的utf-8 content = f.read()#如果open时使用的encoding和文件本身的encoding不一致的话,那么这里将将会产生错误 f.write('你想要写入的信息') f.close() 以上的报错信息的意思是:在将Unicode编码成gbk的时候,不能将Unicode u'\xa0'编码成gbk。 这里,我们需要弄清楚gb2312、gbk和gb18030三者之间的关系 GB2312:6763个汉字 GBK:21003个汉字 GB18030-2000:27533个汉字 GB18030-2005:70244个汉字 所以,GBK是GB2312的超集,GB18030是GBK的超集。 在GB18030字符集中,可以找到u'\xa0'对应的字符。 codecs.open(file,'w',out_enc,errors="ignore").write(new_content) 将Unicode编码(encode)成gbk格式,但是注意encode函数的第二个参数,我们赋值"ignore",表示在编码的时候,忽略掉那些无法编码的字符Excel操作Xlwings、pandas、xlsxwritercsv操作读取csv文件,返回的是迭代类型 打开文件,用with打开可以不用去特意关闭file了,python3不支持file()打开文件,只能用open() with open("XXX.csv","r",encoding="utf-8") as csvfile: read = csv.reader(csvfile) for i in read: print(i) 写入csv文件 import csv with open(csvfilename,"w") as file: writer= csv.writer(file, dialect='unix') # windows下用unix就不会有空行了 #dialect为打开csv文件的方式,默认是excel,delimiter="\t"参数指写入的时候的分隔符 csvwriter = csv.writer(datacsv,dialect = ("excel")) #csv文件插入一行数据,把下面列表中的每一项放入一个单元格(可以用循环插入多行) csvwriter.writerow(["A","B","C","D"]) 使用DictReader可以像操作字典那样获取数据,把表的第一行(一般是标头)作为key。可访问每一行中那个某个key对应的数据。 import csv filename = 'F:/Jupyter Notebook/matplotlib_pygal_csv_json/sitka_weather_2014.csv' with open(filename) as f: reader = csv.DictReader(f) for row in reader: # Max TemperatureF是表第一行的某个数据,作为key max_temp = row['Max TemperatureF'] print(max_temp) #每一行为key,value的记录,针对每一行均为键值对的特殊情形,这里默认认为第一列为所构建的字典的key,而第二列对应为value,可根据需要进行修改 def row_csv2dict(csv_file): dict_club={} with open(csv_file)as f: reader=csv.reader(f,delimiter=',') for row in reader: dict_club[row[0]]=row[1] return dict_club 使用DictWriter类,可以写入字典形式的数据,同样键也是标头(表格第一行)。 import csv headers = ['name', 'age'] datas = [{'name':'Bob', 'age':23}, {'name':'Jerry', 'age':44}, {'name':'Tom', 'age':15} ] with open('example.csv', 'w', newline='') as f: # 标头在这里传入,作为第一行数据 writer = csv.DictWriter(f, headers) writer.writeheader() for row in datas: writer.writerow(row) # 还可以写入多行 writer.writerows(datas)字符串操作strip()用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。声明:s为字符串,rm为要删除的字符序列s.strip(rm) 删除s字符串中开头、结尾处,位于 rm删除序列的字符s.lstrip(rm) 删除s字符串中开头处,位于 rm删除序列的字符s.rstrip(rm) 删除s字符串中结尾处,位于 rm删除序列的字符注意:当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' ')该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。也可用replace("\n", ""),后边的串替换掉前边的split() 函数拆分字符串将字符串转化为列str.split(str="", num=string.count(str))字典排序collections中Counter类collections模块自Python 2.4版本开始被引入,包含了dict、set、list、tuple以外的一些特殊的容器类型分别是:OrderedDict类:排序字典,是字典的子类。namedtuple()函数:命名元组,是一个工厂函数。Counter类:为hashable对象计数,是字典的子类。deque:双向队列。defaultdict:使用工厂函数创建字典,使不用考虑缺失的字典键。Counter类则一般用于跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。计数器的更新(update和subtract)当计数值为0时,并不意味着元素被删除,删除元素应当使用delelements():返回一个迭代器。元素被重复了多少次,在该迭代器中就包含多少个该元素。元素排列无确定顺序,个数小于1的元素不被包含。most_common([n]):返回一个TopN列表。如果n没有被指定,则返回所有元素。当多个元素计数值相同时,排列是无确定顺序的。.copy()拷贝算术和集合操作:+、-、&、|操作也可以用于Counter。其中&和|操作分别返回两个Counter对象各元素的最小值和最大值。需要注意的是,得到的Counter对象将删除小于1的元素。常用操作:sum(c.values()) # 所有计数的总数c.clear() # 重置Counter对象,注意不是删除list(c) # 将c中的键转为列表set(c) # 将c中的键转为setdict(c) # 将c中的键值对转为字典c.items() # 转为(elem, cnt)格式的列表Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象c.most_common()[:-n:-1] # 取出计数最少的n-1个元素c += Counter() # 移除0和负值pathlib处理windows、linux、mac跨平台程序的路径不统一问题pathlib能够很快很容易的做出大多数标准的文件操作: from pathlib import Path filename = Path("source_data/text_files/raw_data.txt") print(filename.name) # prints "raw_data.txt" print(filename.suffix) # prints "txt" print(filename.stem) # prints "raw_data" if not filename.exists(): print("Oops, file doesn't exist!") else: print("Yay, the file exists!") 可以用pathlib准确地将Unix路径转换成Windows格式的路径: from pathlib import Path, PureWindowsPath filename = Path("source_data/text_files/raw_data.txt") # 将路径转换为 Windows 格式 path_on_windows = PureWindowsPath(filename) print(path_on_windows) # prints "source_data\text_files\raw_data.txt" 想在代码中安全地使用反斜杠符号,可以将路径声明为Windows格式,pathlib会将它转换为适用当前操作系统的格式: from pathlib import Path, PureWindowsPath # 由于已明确声明路径在Windows格式中,因此可以用斜杠符号 filename = PureWindowsPath("source_data\\text_files\\raw_data.txt") # 将路径转换为适用当前操作系统的正确格式 correct_path = Path(filename) print(correct_path) # 在Mac和Linux上打印 "source_data/text_files/raw_data.txt" # 在Windows上打印"source_data\text_files\raw_data.txt" 用pathlib解决相对文件路径,解析网络分享路径和生成file://urls等这些问题。这里举个例子,只需两行代码就能让你在浏览器上打开一个本地文件: from pathlib import Path import webbrowser filename = Path("source_data/text_files/raw_data.txt") webbrowser.open(filename.absolute().as_uri())python中的三个读read(),readline()和readlines()文件对象提供了三个"读"方法: .read()、.readline() 和 .readlines()。每种方法可以接受一个变量以限制每次读取的数据量,但它们通常不使用变量。 .read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。然而 .read() 生成文件内容最直接的字符串表示,但对于连续的面向行的处理,它却是不必要的,并且如果文件大于可用内存,则不可能实现这种处理。.readline() 和 .readlines() 非常相似。它们都在类似于以下的结构中使用:Python .readlines() 示例fh = open('c:\\autoexec.bat') for line in fh.readlines(): print line.readline() 和 .readlines() 之间的差异是后者一次读取整个文件,象 .read() 一样。.readlines() 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for ... in ... 结构进行处理。另一方面,.readline() 每次只读取一行,通常比 .readlines() 慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用 .readline()。爬虫相关selenium模块这个模块一般用来模拟浏览器操作使用Xpath定位模拟登录from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.set_headless() options.binary_location = "./chrome/chrome.exe" driver = webdriver.Chrome(chrome_options=options, executable_path="chromedriver.exe", ) login_url = 'http://192.168.254.1/doc/page/login.asp' driver.get(login_url) print(driver.title) driver.find_element_by_xpath('//*[@id="username"]').clear() driver.find_element_by_xpath('//*[@id="username"]').send_keys('admin') driver.find_element_by_xpath('//*[@id="username"]').clear() driver.find_element_by_xpath('//*[@id="password"]').send_keys('1qaz2wsx') driver.find_element_by_xpath('//*[@id="login"]/table/tbody/tr/td[2]/div/div[5]/button').click() current_page = driver.current_url print(current_page) if current_page == login_url : print('GG')selenium指定浏览器程序位置与浏览器驱动位置1.Using Options Class:from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.binary_location = "C:/Program Files (x86)/Google/Chrome/Application/chrome.exe" driver = webdriver.Chrome(chrome_options=options, executable_path="C:/Utility/BrowserDrivers/chromedriver.exe", ) driver.get('http://google.com/')2.Using DesiredCapabilities Class:from selenium import webdriver from selenium.webdriver.common.desired_capabilities import DesiredCapabilities cap = DesiredCapabilities.CHROME cap = {'binary_location': "C:/Program Files (x86)/Google/Chrome/Application/chrome.exe"} driver = webdriver.Chrome(desired_capabilities=cap, executable_path="C:\\Utility\\BrowserDrivers\\chromedriver.exe") driver.get('http://google.com/')3.Using Chrome as a Service:from selenium import webdriver import selenium.webdriver.chrome.service as service service = service.Service('C:\\Utility\\BrowserDrivers\\chromedriver.exe') service.start() capabilities = {'chrome.binary': "C:/Program Files (x86)/Google/Chrome/Application/chrome.exe"} driver = webdriver.Remote(service.service_url, capabilities) driver.get('http://www.google.com')json模块将程序生成字符串以字典格式写入文件中时,使用json.dumps()*将将 Python 对象编码成 JSON 字符串。可以避免字典的 value 中有引号*、格式不标准等问题。json转码格式参数解释obj要存入json文件的python对象 fp文件句柄 ensure_ascii设置为False的话才可以把中文以中文的形式存到文件里,否则会是’\xXX\xXX’这种 indent缩进的空格数,设置为非零值时,就起到了格式化的效果,比较美观 #将json文本转换为dict字典输出 json_str = json.loads(json_content) #将dict字典转换为json文本保存 json.dumps(json_str, ensure_ascii=False, indent=4) # 使用eval函数将字符串转换为字典 test = eval(Bookmarks_)mechanize模拟浏览器发送请求,可以根据html构造提交请求hackhttp相关https://github.com/BugScanTeam/hackhttp一款 Python2.7 语言的 HTTP 第三方库,除众多基础功能外,hackhttp 支持直接发送 HTTP 原始报文,开发者可以直接将浏览器或者 Burp Suite 等抓包工具中截获的 HTTP 报文复制后,无需修改报文,可直接使用 hackhttp 进行重放。hackhttp 使用连接池技术,在应对大量请求时自动对连接进行复用,节省建立连接时间与服务器资源,这种天生的特性,在编写爬虫时尤为显著python3 requests模块的学习1.模拟登陆获取登录成功后的cookies,并格式化。把它转换成一个包含元组的列表,然后用合适的分隔符连接起来就好了 resp = requests.get(url) cookies = resp.cookies login_cookies = '; '.join(['='.join(item) for item in rep.cookies.items()]) 可以利用postman直接生成代码 s = requests.Session() # 可以在多次访问中保留cookie s.post(login_url, {'username':username, 'password': password,}, headers=headers) # POST帐号和密码,设置headers r = s.get(url) # 已经是登录状态了2.网站编码问题import requests r = requests.get('http://blog.sina.com.cn') r.encoding = 'utf-8' #这里添加一行 res.content.decode("utf8") 也就是说,如果你想取文本,可以通过r.text。返回的是Unicode型的数据。 如果想取图片,文件,则可以通过r.content。返回的是bytes型也就是二进制的字节集数据。 resp.json()返回的是json格式数据直接将文件以字节写入r = requests.get(url_file, stream=True) #将文件以流的方式传输 f = open("file_path", "wb") for chunk in r.iter_content(chunk_size=512): #size大小可以自定义,防止文件过大吃内存 if chunk: f.write(chunk) 解决获取网页内容乱码问题(获取编码格式显示为iso-8859)。 req = requests.get(url, headers=headers, timeout=20) html = req.text.encode(req.encoding).decode('utf-8') print(html) 当requests无法识别当前网站的编码,可以自己指定编码。requests在保存字符的时候都是先转换为unicode编码,再用相应字符集转换,所以有时候会存在生僻字无法正常保存的现象,因为字符集中不包含这个字符。 f1 = codecs.open('1.html', 'w', encoding='utf-8') content = html.text.encode() f1.write(content.decode('utf-8')) f1.close3.网站headers问题将网站headers格式化,或者可以利用postman直接生成s = '''Host: web.kompaskarier.com User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3 Cookie: ci_session=我就是cookies Connection: close Upgrade-Insecure-Requests: 1''' s = s.strip().split('\n') s = {x.split(':')[0] : x.split(':')[1] for x in s} print(s) 随机生成header头 import random def get(): user_agent = [ "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", ] #return random.choice(user_agent) header = { 'User-Agent': random.choice(user_agent), 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en-US,en;q=0.5', 'Connection': 'keep-alive', 'Accept-Encoding': 'gzip, deflate', } return header4.网站html问题美化html文件,方便正则匹配htmltext = content.replace('\n','').replace('\r','').replace(' ','').replace('\t','') def main(): name1 = input('来吧输入选择的文件名:') soup = BeautifulSoup(open(name1, 'rb'), 'lxml').prettify() content = str(soup) content = content.replace('\n','') content = content.replace('\r','') content = content.replace(' ','') content = content.replace('\t','') write_test(content)用chardet判断字符编码的方法实例使用中,chardet.detect()返回字典,其中confidence是检测精确度,encoding是编码形式(1)网页编码判断: <span data-wiz-span="data-wiz-span" style="font-size: 1rem;">>>> import urllib >>> rawdata = urllib.urlopen('http://www.google.cn/').read() >>> import chardet >>> chardet.detect(rawdata) {'confidence': 0.98999999999999999, 'encoding': 'GB2312'} (2)文件编码判断 <span data-wiz-span="data-wiz-span" style="font-size: 1rem;">import chardet tt=open('c:\\111.txt','rb') ff=tt.readline() #这里试着换成read(5)也可以,但是换成readlines()后报错 enc=chardet.detect(ff) print enc['encoding'] tt.close()BeautifulSoupfrom bs4 import BeautifulSoup import codecs import re import csv def main(): soup = BeautifulSoup(codecs.open('1.html', 'r', encoding='utf-8'), 'lxml') content = str(soup.prettify) content = content.replace("\n", "") parse_time = '訂單時間:(.*?)</td></tr></table>' parse_shop = '訂單時間:(.*?)</td></tr></table>' parse_text(parse_time, content) def parse_text(parse_re, content): parse_text = re.compile(parse_re, re.S) parse_content = re.findall(parse_text, content) print(parse_content) if __name__ == '__main__': main() # f= codecs.open("1.txt", "w", encoding='utf-8') # f.write(content)协程相关asyncio与aiohttp可以配合queue构建生产者消费者模型使用http://aiohttp.readthedocs.io/en/stable/ 官网client例子import aiohttp import asyncio import async_timeout async def fetch(session, url): async with async_timeout.timeout(10): async with session.get(url) as response: return await response.text() async def main(): async with aiohttp.ClientSession() as session: html = await fetch(session, 'http://python.org') print(html) loop = asyncio.get_event_loop() loop.run_until_complete(main())server例子from aiohttp import web async def handle(request): name = request.match_info.get('name', "Anonymous") text = "Hello, " + name return web.Response(text=text) app = web.Application() app.add_routes([web.get('/', handle), web.get('/{name}', handle)]) web.run_app(app)正则相关import codecs import re with codecs.open('./eg.html',encoding='big5') as f1: content = f1.read() pattern_page = re.compile('/ 共 (.*?) 頁') pages = re.findall(pattern_page,content) print(pages[0]) pattern_content = re.compile('<a href="(.*?)" target="_blank"\>列印\</a>') items = re.findall(pattern_content,content) for item in items: print(item)二进制文件打包cs_freeze py2exe https://github.com/cdrx/docker-pyinstaller linux下使用wine来使用pyinstaller生成exe pyinstaller -F -w run.py https://github.com/takluyver/pynsist wine下使用pyinstaller wine msiexec /i /home/watson/dload/chrome/python-2.7.3.msi wine /home/watson/dload/chrome/pywin32-218.win32-py2.7.exe wine ~/.wine/drive_c/Python27/python.exe ~/bin/pyinstaller-2.0/pyinstaller.py -Fw demo.py验证码识别https://github.com/madmaze/pytesseracthttps://github.com/ZYSzys/awesome-captcha数据库相关sqlite数据库,附带win32api加密数据import sqlite3 # 调用win32api加解密 import win32crypt # sql的插入语句,这里在sql语句中可以在关键位置以英文下的 ? 号作为提前预置值 SQLword = "INSERT INTO logins(username,password) VALUES ('admin', ?)" # 加密前需要先将字符串转为byte pwd = str.encode("test123") # 调用win32api加密 encPwd = win32crypt.CryptProtectData(pwd) # 连接数据库 SqliConn = sqlite3.connect(SqlPath) # 设置游标 cursor = SqliConn.cursor() # 执行sql语句,同时在预置值的地方填充值 cursor.execute(SQLword, [sqlite3.Binary(encPwd)]) # 提交执行 SqliConn.commit() # 调用win32api解密 pwd2 = win32crypt.CryptUnprotectData(blob,None,None,None,0)版本环境管理anaconda将anaconda的bin目录加入PATH,根据版本不同,也可能是~/anaconda3/bin echo 'export PATH="/root/anaconda3/bin:$PATH"' >> ~/.bashrc alias pyana="/root/anaconda3/bin/python" #生成快捷命令 source ~/.bashrc #更新bashrc以立即生效 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes #配置清华镜像 conda create -n py27 python=2.7 #添加2.7版本的Python环境 activate py27(linux: source activate py27) #开启环境 source deactivate py27 #退出环境 conda info -e #命令查看已有的环境 conda remove -n env_name --all #来删除指定的环境 conda install -n py27 lxml #安装依赖 remove 移除依赖 conda install -n py27 anaconda #安装所有包 conda env export > environment.yml #分享环境文件 conda env create -f environment.yml #从文件创建环境 conda update conda #升级conda conda update python #升级python版本pip与easy_install生成requirements.txtpython -m pip freeze >requirements.txt python -m pip install -r requirements.txt pip uninstall [options]安装方法-Windows: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt安装方法-Linux:root用户(避免多python环境产生问题): python2 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt非root用户(避免安装和运行时使用了不同环境): sudo python2 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txtpython出错总结https://github.com/satwikkansal/wtfpythonhttps://github.com/leisurelicht/wtfpython-cn静态方法(@staticmethod),类方法(@classmethod)和实例方法实例方法:正常def()函数静态方法(@staticmethod):用于类中的def()函数,不用传递self,封装在类里,解决了命名重复的问题。类方法(@classmethod):一般使用类前提都要实例话声明(a=class()),使用这个以后可以不声明直接使用thefuck模块https://github.com/nvbn/thefuck 命令行错误弥补补全功能app开发https://github.com/kivy 类wxpython的app开发工具,win linux mac ios android跨平台支持
-
把百万字小说藏进图片 再也不担心麻麻检查了 原理图片存储格式程序使用 Windows BMP 真彩色位图格式,其三个字节代表一个像素,其中每个字节分别代表了这个像素的颜色分量,分别是蓝色 B、绿色 G、红色 R文字的 unicode 序号此处比较简单,直接用 Python 自带两个函数 ord()、chr()ord():可以得到一个字在 unicode 字符表的序号chr():可以根据序号得到对应的文字两者互为逆运算位图的存储信息就是像素,而像素就是数字信息,我们就可以将文字转换后的序号当作一个像素来处理So,理论知识就是如上,下面我们开始写 Bug 了文字转图片txt 文件自备#coding: utf-8 from PIL import Image import math def encode(text): str_len = len(text) # 获取文件的字符长度即字数 width = math.ceil(str_len**0.5) # 开方字数以得到需要生成图片的长宽 im = Image.new("RGB", (width, width), 0x0) x, y = 0, 0 for i in text: index = ord(i) # 将序号拆分到G,B,G:位与序号屏蔽低8位,高8位不变并向右位移8位,B: 序号保存低8位 rgb = ( 0, (index & 0xFF00) >> 8, index & 0xFF) im.putpixel( (x, y), rgb ) if x == width - 1: x = 0 y += 1 else: x += 1 return im if __name__ == '__main__': with open("三体全集.txt", encoding="utf-8") as f: all_text = f.read() im = encode(all_text) im.save("out.bmp") 图片转文字#coding: utf-8 from PIL import Image def decode(im): width, height = im.size lst = [ ] for y in range(height): for x in range(width): red, green, blue = im.getpixel((x, y)) if (blue | green | red) == 0: # 按位或运算 break # 还原序号 index = (green << 8) + blue lst.append( chr(index) ) return ''.join(lst) if __name__ == '__main__': all_text = decode(Image.open( "out.bmp","r")) with open("decode.txt", "w", encoding = "utf-8") as f: f.write(all_text) 成果
-
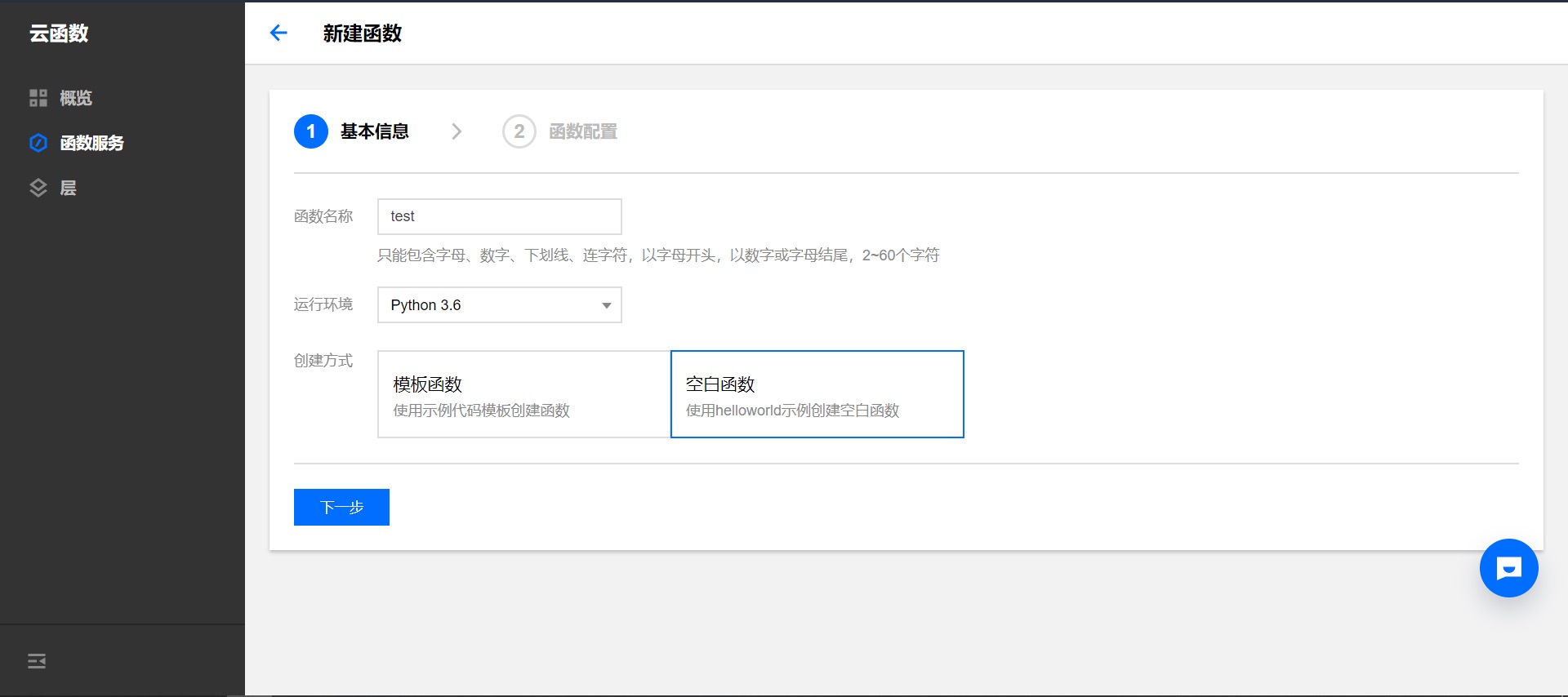
网易云音乐多账号全自动升级,彻底解放双手 引言之前有大佬做了一个windows的界面软件可以刷听歌数量来达到快速升级的目的,用起来挺爽的,即使是每天只需要打开软件登陆打卡就行,但总会忘记,为了达到全自动的目的,@ZainCheung 大大动手做了一个python脚本,可以放在服务器上运行,从此不用再去管它,每天它都会自动去打卡听完300首歌,并且可以多账号使用(理论上可以达到几百个),每天会向微信发送消息汇报任务进度。一、总体介绍这个项目可以做到的功能有:每天自动登陆听完300首歌每天自动向你的微信推送听歌任务进度这个项目分为Python客户端和API接口(服务器),一共两个项目,各有三种部署方法。Python项目的部署最简单的是云函数法,API项目的部署最简单的是直接复制项目法自己搭建API和申请Server酱并不是并须的,没有的话项目也可以运作,只是开发者觉得自己搭建API比较安全,用别人的API别人悄悄加后门你都不知道,当然开发者的API已经公开并且所有代码都开源了,肯定是没有后门的,大家可以拿去用。至于Server酱是为了让你每天知道进度以及项目有没有出问题,也不是必须要加的。所以你想快速使用的话,可以直接看部署Python项目的云函数法和后面的部分,部署API项目可以不看。当你成功运作项目后如果想学习自己搭建API接口再回来看API这一部分。无论采取哪一种方式部署,都要看配置账号这一部分,很简单却也很重要!!!二、部署Python项目的三种方法Python项目地址:https://github.com/ZainCheung/netease-cloud① 云函数全民升级时代来了!项目支持了云函数!!!什么是云函数?就是可以让你没有服务器、本地电脑不用下载Python也可以使用这个项目,而且还是白嫖!既解决了很多人部署的麻烦,也给了那些被劝退的朋友回来的勇气,十分钟便可以全部弄完。1. 进入云函数这里拿腾讯云的云函数做个案例,没有的可以免费开通一下,地址:https://console.cloud.tencent.com/scf/list-create?rid=1&ns=default2. 新建函数函数名随意,运行环境选Python 3.6,创建空白函数,然后下一步3. 上传代码确保环境为python 3.6,执行方法改为:index.main,提交方式一定要选本地文件夹,然后从GitHub项目克隆Zip压缩包,解压成文件夹,然后点击这个上传把文件夹上传进来,完了后点击下面的高级设置。4. 高级设置内存用不了太大,64MB就够了,超时时间改为最大的900秒,然后点击最下面的完成。5. 配置账号自己改下init.config里的账号密码以及Server酱密匙,用到多账号的也要配置account.json,做完后点击保存并测试。如果你的配置没有错,稍等几分钟便可以看到结果,在此期间不要刷新页面。结果会在自行日志里。6. 设置定时点击左边的触发管理,然后新建触发器,触发周期为自定义,表达式就是每天的什么时候做任务,我选择的早上8点30分,可以自行修改,填好后点击提交即可,到此你的每日听歌项目便部署完成,感谢使用!!② 本地使用本地部署需要电脑下载并安装配置好Python1. 下载项目克隆项目到本地git clone https://github.com/ZainCheung/netease-cloud.git或者fork本项目到你的仓库进行克隆又或者在项目仓库直接下载ZIP压缩包,这些都是可以的2. 安装依赖需要安装的依赖目前只有一个request,如果运行报错缺少什么模块就给什么模块加进requirements.txt中pip install -r requirements.txt3. 配置账号见后文4. 启动程序程序需要python3的运行环境,如果没有请自行下载安装配置,,启动程序前一定要先配置账号,然后再启动程序python main.py③ 服务器部署推荐使用宝塔面板,在宝塔应用商店里面有一个Python项目管理器,下载安装,并选择3.0以上版本,推荐3.7.2版本.1. 下载安装Python项目管理器2. 新建项目这里的netease-cloud就是这个项目的文件夹,我给放在了/www/wwwroot/路径下了,可见我这里下载安装的是3.7.2版本的python框架选择Python,启动方式也为Python,启动文件选择main.py端口不用填,勾选安装模块依赖,是否要开机启动自己随意咯,然后确定。3. 确定运行状态这时候项目就开始在运行了,就可以去项目在文件夹的路径,找到run.log即可查看运行日志部署前也要记得先配置,然后再部署三、部署API接口的三种方法建议新手使用自动托管方式,可以完全不需要编程基础即可搭建api接口,推荐使用网站:https://glitch.com/这个网站是国外的,名气也很大,在上面托管网站的有几百万,免费使用,缺点就是速度没有国内的服务器快,还有就是如果没有访问了,一定时间后会进入休眠,等待下一次请求到来后需要等待几秒的解冻时间。不过这些对这个项目并没有什么影响,所以可以放心部署。API项目地址:https://github.com/ZainCheung/netease-cloud-api下面三种方法,第一种第二种最简单但速度慢,而且需要你有网站账号,第三种访问速度快但需要你有服务器,大家自己取舍,但基本上有服务器了都想自己搭建吧,大家随意① fork项目并从GitHub导入fork这个API项目到你的仓库打开网站注册并登陆,新建项目,选择从GitHub导入,地址为本项目的git地址修改你的glitch项目名,例如:netease-test那么你的接口名为“项目名.glitch.com”:https://netease-test.glitch.me/访问你的接口看到欢迎页面即部署成功使用这种方式部署网站接口,0成本且快速可用,且不用担心环境部署运维等问题,当然如果有条件用自己的服务器搭建也是可以的。1. fork项目跳过 Star2. 导入项目填入你的的git地址,地址在你的Github项目的clone按钮里,要用https改自己项目名② 直接复制项目或者可以直接复制一份这个API项目成为你的项目,进入开发者的api服务器: https://glitch.com/edit/#!/netease-cloud-api 选择右上角的 Remix to Exit,即可成为你自己的项目,你便可以对代码进行修改,自定义你的域名③ 服务器部署部署到服务器,对于新手还是比较建议安装宝塔面板,然后就可以在浏览器中进行界面化操作,免得有的人不会Linux的命令行。1. 下载PHP2. 添加网站填入你提前在你的域名运营商解析的域名,可以是子域名比如,api.xxxxxx.com,写个网站备注,然后根目录选择到下载的项目路径,FTP不创建,数据库不创建默认utf-8就行,程序类型PHP,版本选择下载的版本,提交即可运行你的网站。运行网站这里演示域名为test.com,然后在浏览器里输入你的网站地址,看到欢迎页面即为部署成功四、配置账号为了保护账号信息,所有的账号密匙都打上了*号,使用时请换成自己的账号打开init.config文件,进行配置# setting.config(UTF-8)第一句注释是为了声明编码格式,请不要删除该行注释1. 账号[token] # 网易云音乐账号(手机号/网易邮箱) account = 150******** # 密码,明文/MD5,建议自己去MD5在线加密网站给密码加密,然后填到下面 # 明文例如:123456abcd # MD5例如:efa224f8de55cb668cd01edbccdfc8a9 password = bfa834f7de58cb650ca01edb********token区域下存放个人账号信息,account存放网易云账号,password存放密码注意,这里密码填写类型与后面的md5开关相关联,具体见后面介绍2. 设置[setting] # 开关的选项只有 True 和 False # 打卡网站的网址,如果失效请提issue:https://github.com/ZainCheung/netease-cloud-api/issues/new api = https://netease-cloud-api.glitch.me/api是指提供接口的服务器地址,这里提供一个Demo,源码也已经全部开源,如有对项目存在疑问欢迎查看源码,项目地址:ZainCheung/netease-cloud-api另外想快速拥有一个一模一样的api服务并且使用自己定义的域名,那么可以按照上面项目的教程自己快速搭建2-1. MD5# 密码是否需要MD5加密,如果是明文密码一定要打开 # true 需要, 则直接将你的密码(明文)填入password,程序会替你进行加密 # false 不需要, 那就自己计算出密码的MD5,然后填入上面的password内 md5Switch = falsemd5开关,如果自己不会加密md5,那么将这个开关置为true,并且将你的密码(明文)填入password,程序会为你加密。如果已经知道密码的md5,则将这个开关置为false,将md5填入上面的password内自己制作MD5时一定要是32位小写!!!2-2. 多账号# 是否开启多账号功能,如果打开将会忽视配置文件里的账号而从account.json中寻找账号信息 # 如果选择使用多账号,请配置好account里的账号和密码,即account和password,而sckey不是必需的,如果为空则不会进行微信推送 # 介于账号安全着想,account.json中的密码必须填写md5加密过的,请不要向他人透露自己的明文密码 peopleSwitch = false这个开关是为那些拥有多账号或者准备带朋友一起使用的朋友准备的,正如注释所说,如果你有多个账号,都想使用这个服务,那么可以打开peopleSwitch置为true,那么配置文件里的账号就会被程序忽略,直接读取account.json中的账号信息,关于account.json的配置在后面。2-3. 微信提醒# Server酱的密匙,不需要推送就留空,密匙的免费申请参考:http://sc.ftqq.com/ sckey = SCU97783T70c13167b4daa422f4d419a765eb4ebb5ebc9********Server酱,是一个可以向你的微信推送消息的服务,并且消息内容完全自定义,使用之前只需要前往官网,使用GitHub登陆,扫码绑定微信,便可以获得密匙,从此免费使用Server酱3. 配置多账号第一次打开account.json,内容会是这样[ { "account": "ZainCheung@163.com", "password": "10ca5e4c316f81c5d9b56702********", "sckey": "SCU97783T70c13167b4daa422f4d419a765eb4ebb5ebc9********" }, { "account": "150********", "password": "bfa834f7de58cb650ca01edb********", "sckey": "SCU97783T70c13167b4daa422f4d419a765eb4ebb5ebc9********" }, { "account": "132********", "password": "f391235b15781c95384cd5bb********", "sckey": "SCU97783T70c13167b4daa422f4d419a765eb4ebb5ebc9********" } ]可见里面是一个数组文件,成员为账号对象,对象有三个属性,分别是账号、密码、Server酱密匙。不同的账号对应不同的密匙,在做完这个账号的任务后会给这个密匙绑定的微信发送消息提醒,如果留空则不提醒,留空也请注意语法,记得加双引号,列举一个正确的案例[ { "account": "ZainCheung@163.com", "password": "10ca5e4c316f81c5d9b56702********", "sckey": "" }, ]可见这里的sckey为空,那么完成任务后便不会发送消息提醒,如果不确定是否成功可以查看日志五、效果演示使用前可以看到是9027首使用后是9327首,刚好涨了300首微信提醒微信提醒依赖于Server酱,这是个很奈斯的工具,个人开发的一个项目,对所有人保持免费开放,需要使用GitHub登陆,然后绑定微信,拿到你的密匙,填入到配置文件的sckey中,或者多账号文件account.json中提示的内容也可以自行修改,main.py文件的第143行左右的diyText函数里的content为提示内容,里面可以自定义提示内容,比如你不是考研党就把考研那一行删去,以及每日一句,,等等,如有需要尽情改。看一下效果:六、下载地址Python项目地址:https://github.com/ZainCheung/netease-cloudapi接口项目地址:https://github.com/ZainCheung/netease-cloud-apiapi的Demo演示地址:https://netease-cloud-api.glitch.me/api在线服务器:https://glitch.com/edit/#!/netease-cloud-api七、查看日志只有本地部署和服务器部署才会生成日志文件,而用云函数搭建的不会有这个run.log文件,如需查看日志可以查看云函数内置的日志。日志文件记录了程序运行的状况,程序运行中生成的所有记录都会保存在日志文件中,第一次克隆项目时,不会看到run.log日志文件,而在程序第一次运行时才会生成,下面看一下我在服务器上的日志:八、其他1. Server酱一定要绑定微信才会有效果Server酱的官网地址:http://sc.ftqq.com/2. MD5制作时选择32位小写!!!在线“制作”MD5:https://tool.chinaz.com/tools/md5.aspx比较建议大家使用MD5,因为别人即使知道了你的MD5,也很难还原你的密码,相对而言要安全很多,而原密码在你制作MD5时就被隐藏起来了,只有你一个人知道密码3. 修改main.py如果你的等级比较高,然后使用这个发现每次都没有听满300首,那么你可以修改程序的start函数(165行左右)的打卡次数,将3改大点,比如改到6就可以打卡6次for i in range(1,3):如果你嫌打卡速度慢了,可以修改休眠时间,30秒改为10秒之类的,请自行调试time.sleep(30)4. 可用性可能有人会说,直接使用网页或者电脑程序每天打卡不就好了,干嘛还要脚本。是的,使用网站和程序确实可以做到一样的效果,不过我懒啊,还总是忘事,所以就让它彻底全自动化,可能也有不少人愿意像我这样折腾一番,然后就可以坐享其成一劳永逸,每天坐等微信提醒就行。5. 初衷使用网易云也有挺久了,听的歌也挺多,但总是会听重复的歌,而重复的歌又不算进等级里去,所以还是很想升级的。6. 反馈欢迎到GitHub提Issue或者在吾爱帖子下提问题,遇到程序报错可以截图或者复制报错信息。九、项目结构|-- 项目文件夹 |-- LICENSE |-- README.md |-- account.json |-- init.config |-- main.py |-- requirements.txt |-- run.logLICENSE:开源许可证README.md:项目自述文件account.json:账号存放文件init.config:配置文件main.py:主程序requirements.txt:依赖清单run.log:运行日志十、声明感谢 @ZainCheung 大大,本项目的所有脚本以及软件仅用于个人学习开发测试,所有网易云相关字样版权属于网易公司,勿用于商业及非法用途,如产生法律纠纷请自行个人解决。
-
一个用python写的整合表格的小工具 功能把一个文件夹下的表格汇总到一个表格里代码# -*- coding: utf-8 -*- import pandas as pd import numpy as np import os,csv,sys adr = os.path.dirname(os.path.realpath(sys.argv[0]))#获取当前文件所在目录 __file__和realpath的差别,https://blog.csdn.net/qq_41817302/article/details/88684703 file_list =[] def file_name(file_dir): for root, dirs, files in os.walk(file_dir):#files:当前路径下所有非目录子文件。root,当前目录路径。dirs:当前目录下的所有子目录 for file in files:#遍历当前路径下所有非目录子文件 if os.path.splitext(file)[1] == '.xlsx':#通过splitext把后缀跟名字分开,以列表格式,判断你要的格式,然后把路径加入进列表 file_list.append(os.path.join(root,file)) return file_list#返回列表 file_name(adr) print('是否整合以下所有表格:') for a in file_list: print(a)#打印当前文件夹的所有xlsx文件路径 print(input('任意键继续')) excel_num = pd.ExcelFile(file_list[0])#读取列表里的第0个路径,使用sheet_name获取工作表数量 header_data = pd.read_excel(file_list[0],sheet_name=len(excel_num.sheet_names)-1,header=0)#读取文件 tr_header = header_data.columns#使用colunms获取每一列的列名 header_list =np.array(tr_header).tolist()#使用tolist转化成列表 #print(header_list) f = open('汇总.csv','a',newline='',encoding='utf-8') #创建一个汇总表格 write = csv.writer(f) #实例化对象 write.writerow(header_list) for i in file_list: excel = pd.ExcelFile(i) #实例化对象通过ExcelFile 获取下列sheet的个数,直接使用excel.sheet_names可以获取sheet名字 read_file = pd.read_excel(i,sheet_name=len(excel.sheet_names)-1,header = 0) #通过read_excel读取,i 是路径 ,sheet_name是要打开的工作簿,可以是工作簿名字,也可以是索引,col确定标签行 #print(read_file) #number = read_file.shape[0]-1 #read_file.drop([number],inplace=True,axis=0) #删除标签行里指定字符的行,axis=0为行,1为列,inplace为重新赋值 tr_read_file = np.array(read_file) #通过array以及tolist把DF转化为list read_list = tr_read_file.tolist() print(read_list) for i in read_list: #把获取到的数据写入 write.writerow(i) f.close() #关闭表格演示把表格和py文件放在一个文件夹下运行,运行结束就会出现一个汇总.csv的表格
-
学小易 Python版 前言通过调用百度云的OCR文字识别提取文字,实现以图搜题功能。支持目前主流的大部分图片格式,如:PNG,JPG,BMP,JPEG等.支持登录的船新版本,避免了多人使用同一token导致的账号异常及封号现象. 登录获取到的token将会存到token.txt中 若token.txt中存在token,将直接跳过登录过程。代码# -*- coding: utf-8 -*- import requests import os from aip import AipOcr #这里调用了百度云智能大脑的图像识别API,以下三个Key均为调用API需要,可在你自己的百度云管理界面查询到 token="" #申明一个全局变量Token APP_ID='16593668' #你的百度云APP_ID APP_KEY='FhqfbBANUQ9H1Q1pj8tS97QH' #你的百度云Key SECRET_KEY='VtPljGlCiXym52xRmiZCoUNX4Z4dsmWT' #你的百度云Secret_Key(老版本百度云的 Access Key) client=AipOcr(APP_ID,APP_KEY,SECRET_KEY) def getanswer(text,token): #一个简单的post请求获取答案内容 if (token==False): return False headers={ "Host":"app.51xuexiaoyi.com", "token":token, "device":"Auhqehd3s6Ml6mXky_5dV-Uv4zsdXeUYY7wKFktkH1ag", "platform":"android", "app-version": "1.0.6", "t":"1592904062239", "s":"e6a47dea8298225b1e9a9366bead8083", "content-type":"application/json;charset=utf-8", "accept-encoding":"gzip", "user-agent":"okhttp/3.11.0" } url="https://app.51xuexiaoyi.com/api/v1/searchQuestion?keyword="+text # data={"keyword":text} res = requests.post(url,headers=headers) # r=res.text.replace('%u',r'\\u').encode('utf-8').decode('unicode_escape') #如果将返回值以文本形式显示本条语句可将usc2转为ansi编码进而正常显示文本内容 r=res.json() #返回的内容本身就是json if(r['code']==200): #判断获取到的内容状态码是不是200(200代表着成功) #print(type(r['data'])) return r['data'] #若成功则返回获取到的问题和答案(返回的类型是列表) else: return r['msg'] #若失败则返回错误信息 def outanswer(li): if isinstance(li,list): #由于获取成功返回的是列表,所以这里先判断是不是列表进而得知是否成功 for i in li: #若成功,则可通过迭代的方式遍历列表 print(" ") print('问题:') #列表中的每个元素都是一个字典,这里通过格式化输出把字典里需要的内容输出 print(i['q']) print(" ") #输出空行为了看起来更方便 print('答案:') print(i['a']) print(" ") print('*'*50) else: print(li) #若参数不为列表,则返回的是错误信息,所以这里可以打印错误信息 def login(): #调用API获取账号的token username=input("请输入账号:") password=input("请输入密码:") url="https://app.51xuexiaoyi.com/api/v1/login?username="+username+"&password="+password headers={ "Host":"app.51xuexiaoyi.com", "device":"Auhqehd3s6Ml6mXky_5dV-Uv4zsdXeUYY7wKFktkH1ag", "platform":"android", "app-version":"1.0.6", "t":"1593008524987", "s":"53029a76022a2f4a52c11f08a84759c0", "Content-Type":"application/json; charset=utf-8", "Accept-Encoding":"gzip", "User-Agent":"okhttp/3.11.0" } res=requests.post(url,headers=headers).json() if (res['code']==200): f=open('token.txt','w+') f.write(res['data']['api_token']) f.close() print("登陆成功!") return res['data']['api_token'] else: return res['msg'] def OCR(imagename): #参数为图片文件路径,函数的功能为获取图片数据,并通过百度云的OCR文字识别提取出图片中的文字. with open(imagename, 'rb') as fp: image=fp.read() retlist=client.basicGeneral(image) text="" #由于百度云的OCR识别将结果作为一个列表进行返回,所以这里通过for循环将列表迭代为一个文本 for i in retlist['words_result']: text=text+i['words'] return text def Ocrmode(): #OCR文字识别模式,可将题目截图到任意目录,输入图片绝对路径一键进行题目提取及答案获取的操作 while True: print("请输入图片路径:") path=input("ocrmode>>>") if(os.path.exists(path)): #检测图片是否存在,若存在,则进行文字识别并查询答案 text=OCR(path) res=getanswer(text,token) outanswer(res) elif path=="exocr" or "EXOCR": return else: print("图片不存在或没有访问权限!") def main(): print('Welcome to "学不易" 输入"exit"或点"x"即可退出') print('直接输入题目即可获取答案,也可输入"OCR"进入图片识别模式') try: f=open('token.txt','r+') token=f.read() f.close() if(token==""): token=login() except: token=login() while True: questions=input(">>>") if len(questions)>=6: res = getanswer(questions,token) outanswer(res) elif questions == 'exit': break elif questions=="ocr" or "OCR": Ocrmode() else: print("题目必须大于6个字符") exit() if __name__ == "__main__": main()
-
通过Python保存央视频某主题的视频地址 代码仅供学习交流使用!!!代码仅供学习交流使用!!!代码仅供学习交流使用!!!Start测试地址:https://v.cctv.com/主要获取的是央视频分类下的视频区,某个主题下的视频地址并保存到文件中暂时不提供视频下载和合并工具的代码!(还不会整)m3u8的链接可以用播放器直接播放,比如 Potplayer 打开链接即可;MP4视频有不同的分辨率,可以选择不同的分辨率进行下载和合并。比如这个视频:https://v.cctv.com/2020/05/31/VIDELxZ6fRrVKzIh0cHiR8v3200531.shtml?spm=C90324.P40KqxTpAJGE.ECW6gIhV6rsX.6源码# -*- coding: utf-8 -*- import requests import time import hashlib import re import json headers = { 'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1' } # 测试地址: # cctv_url = 'https://v.cctv.com/2020/05/31/VIDELxZ6fRrVKzIh0cHiR8v3200531.shtml' cctv_url = input('请输入视频地址:') rs = requests.get(cctv_url, headers) rs.encoding = 'utf-8' html_data = rs.text # title = re.search('<title>(.*?)</title>', html_data).group(1) print('主题:%s' % title) # 解决平台特殊符号问题 new_title = title.replace('/', ' ').replace(':', ':').replace('*', ' ') \ .replace('?', '?').replace('<', ' ').replace('>', ' ').replace('|', ' ').replace('\\', ' ') # rec = re.compile('var guid = "(.*?)";') content = re.search(rec, html_data) # 求出vc guid = content.group(1) vdn_tsp = str(int(time.time())) vdn_vn = "2049" vdn_vc = "" staticCheck = "47899B86370B879139C08EA3B5E88267" vdn_uid = "" # new_str = (vdn_tsp + vdn_vn + staticCheck + vdn_uid) vc = hashlib.md5(new_str.encode(encoding='UTF-8')).hexdigest().upper() # 接口 url_data = f'pid={guid}&tai=ipad&from=html5&tsp={vdn_tsp}&vn=2049&vc={vc}&uid=&wlan=' url = 'https://vdn.apps.cntv.cn/api/getIpadVideoInfo.do?%s' % url_data res = requests.get(url=url, headers=headers) print(res.status_code) data = res.text # 处理请求 start = data.find("'{") end = data.find(";") j_data = json.loads(data[start + 1:end - 1]) # video = j_data['video'] # 保存到文件 with open('%s.txt' % new_title, 'w', encoding='utf-8') as ff: # m3u8地址 ff.write('m3u8地址:\n') ff.write(j_data['hls_url'] + '\n\n') ff.write('MP4地址:\n') for value in video: vv = video[value] if type(vv) == list: for u in vv: video_url = u['url'] print(video_url) ff.write(video_url + '\n')测试效果总结总体来说不难,只需要模拟出请求的参数就基本能拿到和视频地址相关的数据了。
-
python 22行代码简单实现通过分享链接下载无水印视频 python 22行代码简单实现通过分享链接下载无水印视频网上这类工具很多,但是我还是想自己实现一下。前面有做了 PHP 版本,最近在学 Python,顺便也来个。研究了一下,主要流程如下:访问地址:https://v.douyin.com/J8cHNas/ ,自动跳转到一个页面。不用管页面如何,我们可以直接打开 F12 看到请求,稍微看一下,会发现所有的视频信息(包含视频路径、名称、作者等等)都存储在这个请求中:https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6841990853624433920&dytk=直接从接口获取到 video 的链接:https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f4f0000brpq51lahtm68p8nvh6g&ratio=720p&line=0把链接中的playwm替换成play(去掉wm就行),就可以获得无水印的地址了,如:https://aweme.snssdk.com/aweme/v1/play/?video_id=v0200f4f0000brpq51lahtm68p8nvh6g&ratio=720p&line=0注:无水印的视频,只能在移动端播放,所以我们需要在user-agent中模拟手机端的操作。至于如何得出去掉wm就可以无水印的结论,有经验的可以尝试看抖音时抓包,可以得到他的视频链接,简单对比就可以得出结论了。代码# -*- coding: utf-8 -*- import requests import re import json #获取抖音地址 url=input("请输入抖音地址\n") userAgent = "Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36" header = { "Referer": "https://v.douyin.com/", 'User-Agent': userAgent, } #获取到视频id r = requests.get(url,headers = header) url=r.url id=url.split("video/")[1].split("/?")[0] #获取到有水印视频地址 url="https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids="+id r = requests.get(url,headers = header) #获取到无水印视频地址 video=json.loads(r.content)["item_list"][0] url=video["video"]["play_addr"]["url_list"][0] url=url.replace("playwm","play") #开始下载 r = requests.get(url,headers = header) with open(video["desc"]+".mp4", "wb") as code: code.write(r.content) print("下载成功") input("按下回车退出程序")